SISTEMAS DE CONTROL
DE VERSIONES DEL SOFTWARE
SCV
Desarrollo del Software
Aplicación de SCV en el Desarrollo
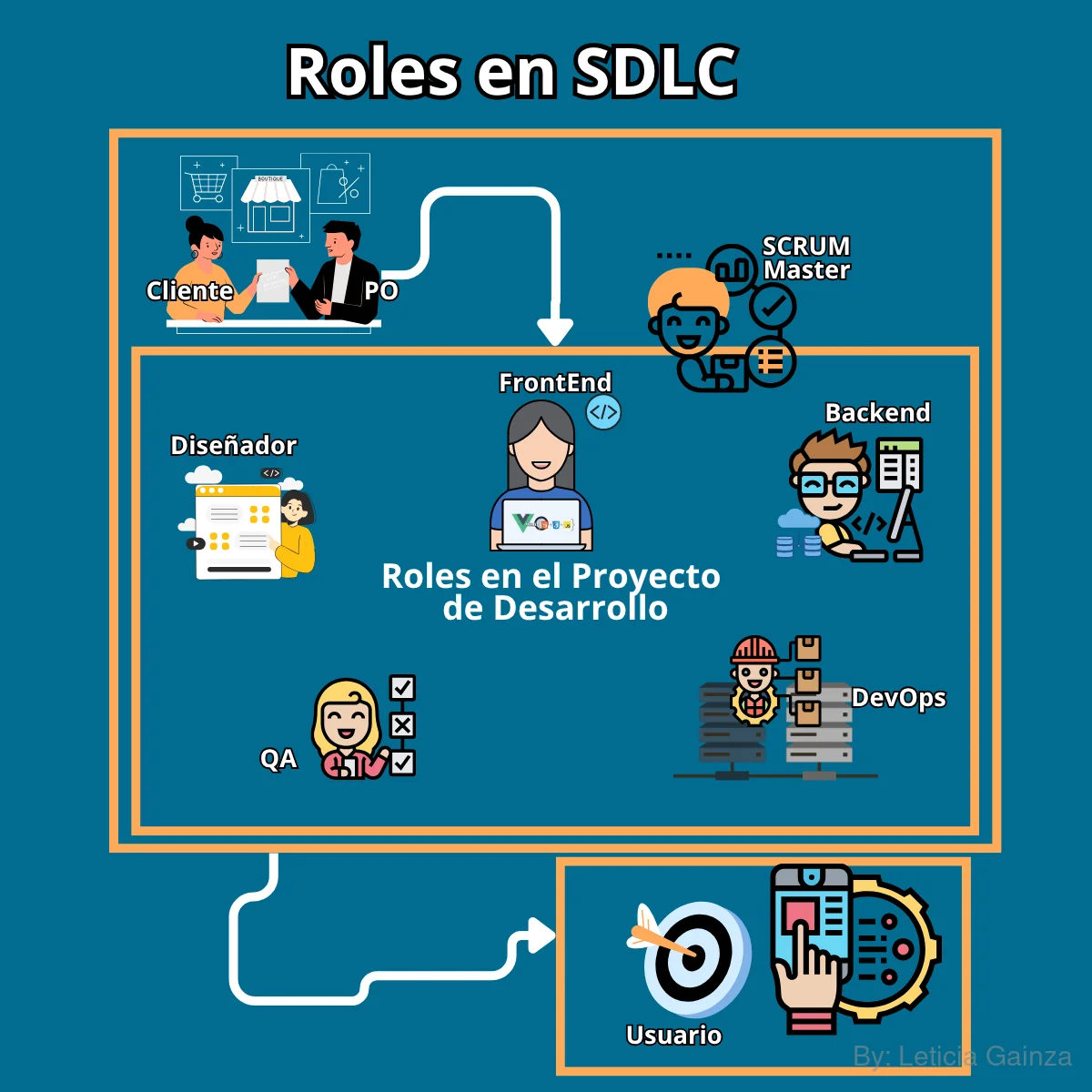
8 Roles Claves en SDLC
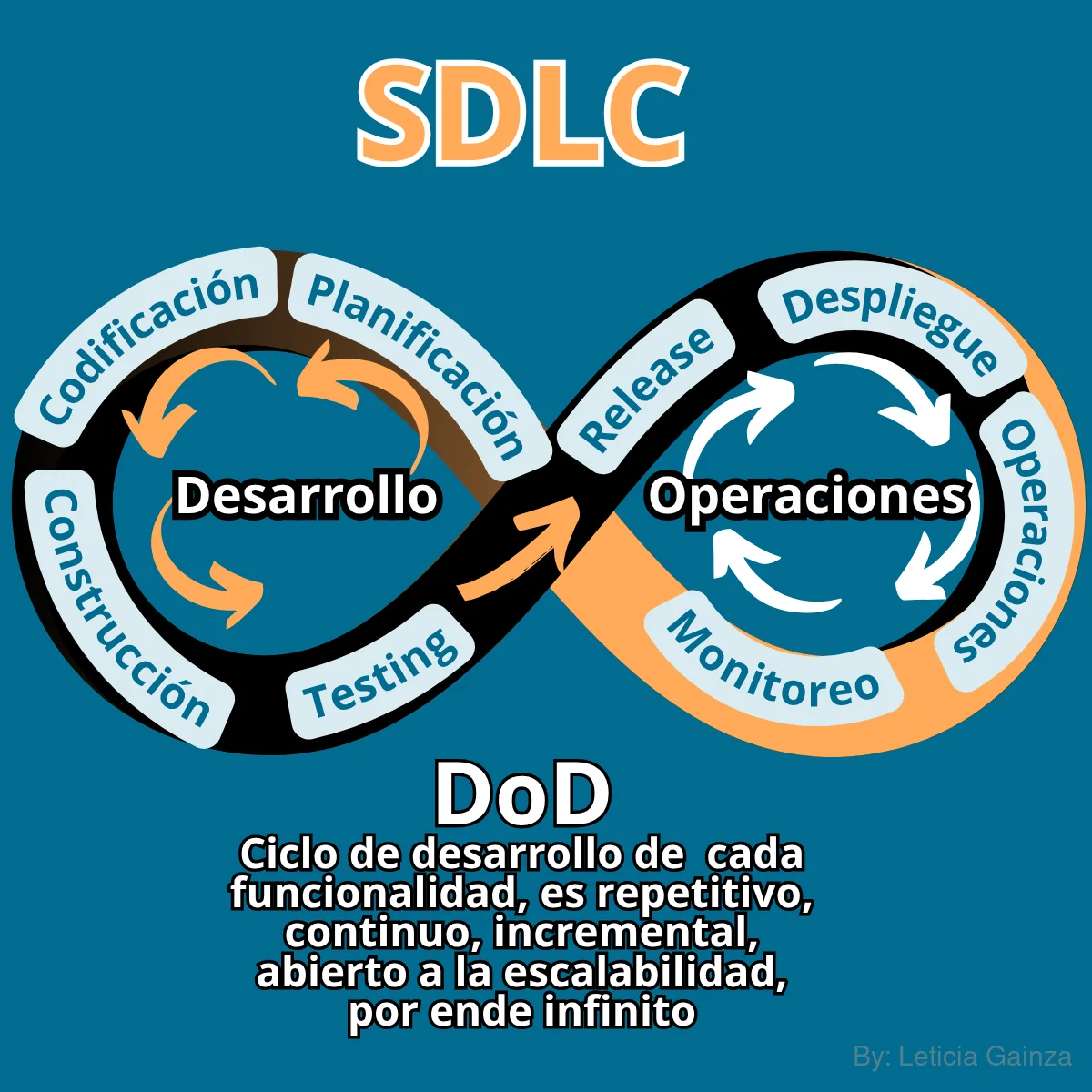
Para poder cumplir con las exigencias del desarrollo de un Software y asegurar el cumplimiento de un ciclo de desarrollo completo hasta entregar un producto de valor ó MVP se organiza lo que se conoce como un "Proyecto de Trabajo", que no es más que organizar toda la infraestructura y las prácticas para el desarrollo de un Software específico, de manera que se puedan implementar todas las etapas de del SDLC durante el desarrollo de un Software completo, ó incluso si se trata de un proyecto para dar mantenimiento y/o crear nuevas funcionalidades para un Software ya existente.
Todo esto parte de la idea de desarrollar el Software por partes o con una arquitectura de microservicios,donde un microservicio se entiende como una pieza de Software o digamos que un mini-Software, que provee una única funcionalidad, del Software total.
Esto permite mejor escalabilidad del sistema, así se puede desarrollar cada funcionaliadad independiente, desacoplada del resto de las funciomnalidades totales del Software, se trabaja el desarrollo de su código y sus cambios individualmente. Esta solución permite que se puedan desarrollar varias funcionalidades, incluso en paralelo, lo que no debería afectar a otras funcionalidades.
Así se cierra un ciclo de dasarrollo y se inicia uno nuevo dentro del mismo Software, de aquí lo de "ciclo" de vida del desarrollo de Software, que además al volver a hacer los ciclos dentro del mismo Software total, permite que se itere sobre el producto en períodos de tiempo "Sprint" donde al final de cada ciclo se entrega un MVP, por lo que el SDLC es "infinito".
¿Cómo se concreta el flujo de trabajo para cumplir el SDLC?
Para explicar el flujo primero debemos hablar de las personas que intervienen en el SDLC, los roles y responsabilidades y luego del flujo en términos técnicos.
Los roles en el SDLC determinan las tareas, o sea quien hace qué, cuándo lo hace, qué aporta y por qué lo hace, etc, cabe precisar para que los roles no trabajan aislados sino como un sistema, por lo que necesitan una sinergia entre sí, digamos que se requieren reglas y normas de interacción, comunicación y cooperación, además de compromiso con el proyecto y respeto mutuo.
En algunas literaturas se clasifican los roles de manera general como los stakeholders del SDLC o partes intersadas y los usuarios finales, los primeros son aquellos roles relacionados con el desarrollo del Software directamente, desde la solicitud del producto, construcción y hasta la entrega final que tienen intereses de negocio, los segundos se refieren a los que consumen el producto, resuelven problemas, pero no tienen intereses de negocio.
En la presente explicación yo, desde mi experiencia, tomo como referencia la Norma ISO 9001: 2018 Sistema de Gestión de Calidad, ya que desde esta perspectiva se considera al usuario final también como un stakeholder.
Desde esta perspectiva el aseguramiento de calidad contempla en su estrategia desde el principio la garantía de cumplimiento de los intereses de usuarios finales, o sea el usuario va a utilizar un producto por los intereses que tenga, según el valor de uso que adquiera con el mismo, por ejemplo si el producto tiene una finalidad de uso personal, profesional o de negocio, el usuario tiene interes para generar valor, por lo que si no se trata de garantizar que un un Software cumpla con esos intereses aún si es funcional, el Software podría ser considerado como un producto de baja calidad.
Digamos que con esta forma de pensar vamos a buscar asegurar la calidad para todos teniendo en cuenta que debemos considerar varios puntos de vista e intereses y no esperar a realizar pruebas de aceptación de usuarios en etapas finales, como único método de garantizar la calidad en relación a los intereses de los usuarios.Los que comento a continuación son roles claves, pero no significa que sean los únicos, esto va a depender de cómo cada empresa organice su Capital Humano y según su estrategia de trabajo, ya que hay roles que pueden hacer tareas específicas de otros, como también hay algunos que sean muy especializados.
Roles y responsabilidades en SDLC:
| Roles | Responsabilidades |
|---|---|
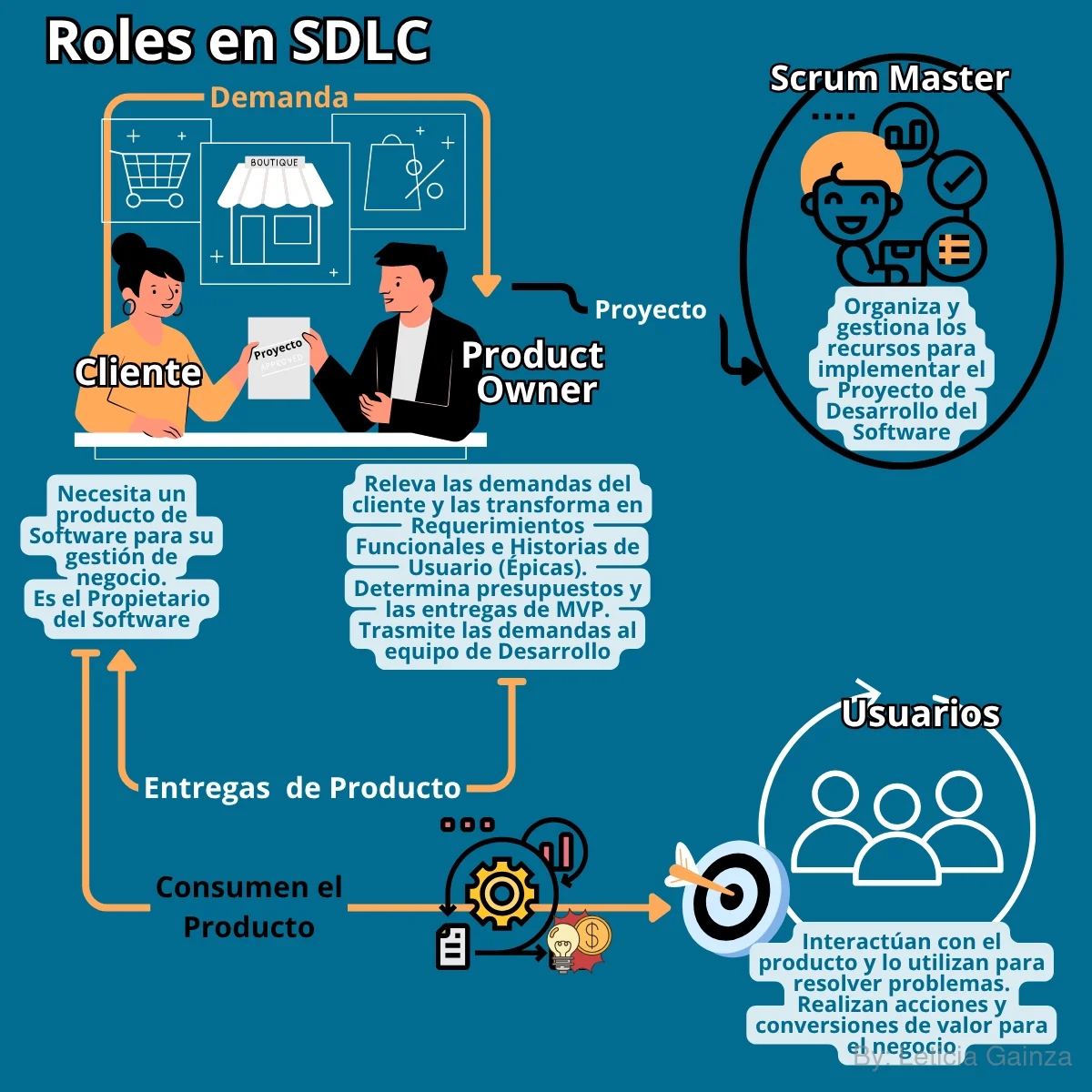
| 1-El Cliente | Es la empresa, negocio o persona que solicita el Software. Plantea sus demandas, lo que surge de una necesidad de negocio, el problema que quiere resolver, el producto que necesita, etc. El Cliente define los requisitos que espera del Software para hacer las conversiones de acciones de su público objetivo en gananacias de negocio, según sus expectativas. El Cliente aporta la financiación para el proyecto, participa en la aprobación de conformidad de su producto mientras se va desarrollando |
| 2-Los Usuarios | Son las personas que van a consumir el producto de Software, para satisfacer sus necesidades, a partir de la solución de problemas reales. Tienen intereses con el producto, ya que este podría gererar valores a partir de su uso. |
| 3-Los Gerentes o Dueños de Producto (Product Manager/Product Owner) | Son los que interactúan directamentecon el cliente para entender y especificar las necesidades del cliente y lo que pretende que haga el Software, respondiendo a sus intereses. Determina en conjunto con el cliente los presupuestos de desarrollo, el tiempo de entrega, el costo, etc. Este rol tiene la reponsabilidad de traducir estas peticiones en requerimientos, o sea cómo se espera que funcione el Software, que o bien estas tareas las puede realizar un rol aparte conocido como el analista que convierte los requerimientos en las grandes historias de usuarios conocidas como épicas, o bien, el análisis de requerimientos, podría estar implícito dentro de las tareas de PO. Luego los requerimientos serán comunicadas al equipo de desarrollo y serán analizados y segmentados para organizar el trabajo en tareas y sub-tareas enfocadas a cada una de las funcionalidades por separadas. Este rol debe garantizar las entregas de producto de Software para el cliente en los tiempos acordados. En resumen: este rol se comunica con el cliente y con el equipo de desarrollo, se asegura de entender la lógica de negocio y lo que se necesita del Software y cómo será usado por el usuario final. Ejemplo: - Necesidad del cliente: Lo que quiere el cliente (vender su marca de zapatos) -Los requerimientos: Lo que se necesita que haga el Software para satisfacer las necesidades del cliente, las funciones que se van a desarrollar ( Mostrar el stock de productos, hacer órdenes de compra, realizar pagos, notificar entregas, etc.) - Traducción a Épicas: Permite conducir el desarrollo del Software según las funcionalides generales que va a tener este y el uso final, luego se van a simplificar en historias de usuarios más atómicas que define cada funcionalidad y sus características, cumpliendo una lógica de negocio (Como usuario del Software quiero poder ver el stock de zapatos, quiero poder comprar zapatos, deseo poder pagar mis compras, etc ) |
| 4-Los Administradores de Proyecto (Scrum Master/Project Manager) | En depencia de la metodología usada podría ser el Scrum Master. Este rol se encarga de gestionar el proyecto, es quien coordina recursos (materiales y humanos) y la estimación de tiempos y esfuerzos, para cumplir el proyecto. Se encarga de organizar los canales de comunicación. La revisión del estado de las tareas, usualmente con reuniones. |
| Roles | Responsabilidades |
|---|---|
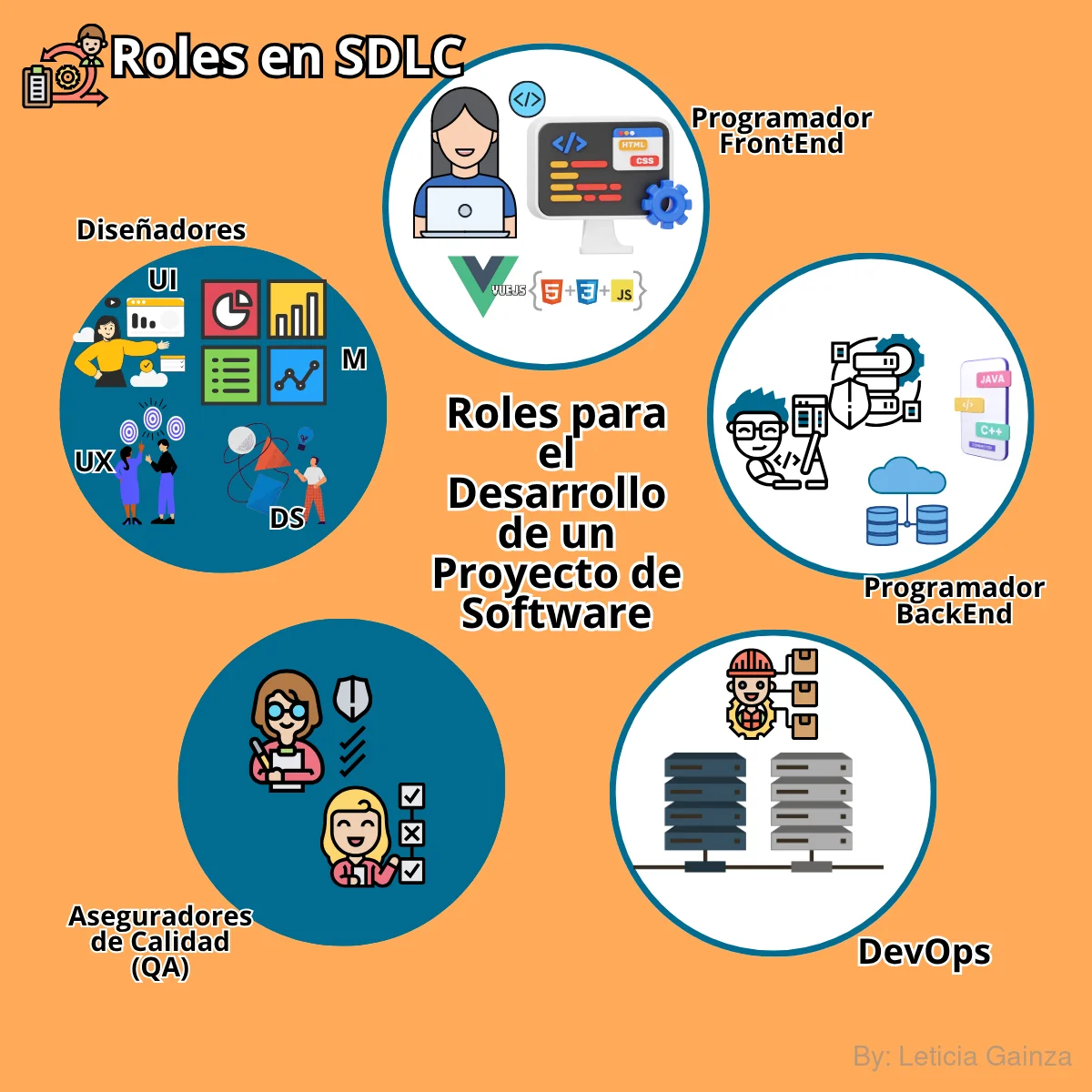
| 5-Los Diseñadores | Son los encargados de crear las interfaces de usuario, los estilos (Diseño UI), diseñan las interacciones de los usuarios con el Software(UX) a partir de representar los requerimientos, además de la comunicación gráfica y la arquitectura del Software (SD), a través de la creación de prototipos, wireframes, mockups, etc. Las mencionadas antes son las principales funciones de los Diseñadores, que o bien se pueden desempeñar en roles separados, o bien una misma persona desarrolla actividades relativas a todos ellos |
| 6-Los Desarrolladores del código fuente del Software o Ingenieros de Software (Developers-Devs) | Son los encargados de traducir los requerimientos/funcionalidades, en todo el código fuente ejecutable del programa de Software, integrarlo, testearlo y desplegarlo. Desarrollan los módulos y componentes del sistema, o sea crean el código, dividido en particiones lógicas en elementos que realizan funciones (aplicando la lógica matemática) y subfunciones específicas, estos módulos se llaman subrutinas o procedimientos, que muestren características funcionales independientes. Digamos que una funcionalidad puede tener varios módulos, en cada módulo se desarrolla una subfunción que contiene las instrucciones para que lograr la ejecución de una característica o feature de la funcionalidad. Por ejemplo hay subrutinas o bloques de código para la entrada de datos de un formulario, que se va a reutilizar para cada campo del formulario, luego hay subrutinas para la validación de condiciones de entrada de datos; esto trabaja sobre una feature de la funcionalidad como el Formulario de Registro de Usuarios, en relación a la funcionalidad de Registro de Usuarios. Usualmente hay desarrolladores de FrontEnd y otros para BackEnd, cada uno puede escribir su código en lenguajes de programación difrentes. Los de FrontEnd programan las funcionaloidades del lado del cliente y los de Backend programan las funcionalidades del lado del servidor, además se suelen encargar de programar las bases de datos y el manejo de las peticiones de las APIs, así como lo niveles de acceso y seguridad. Suelen trabajar usando los frameworks de programación para aplicar estánderes y recursos que permitan reutilizar códigos y evitar la repetición. Esto favorece un trabajo eficaz y eficiente, mientras menos código repetido mayor será el rendimiento de una aplicación, medida en velocidad de funcionamiento y necesidad de recursos para almacenar. |
| 7-Los Aseguradores de Calidad del Software ó QA | Este rol tiene una elevada responsabilidad, ya que debe comprobar y demostrar que el Software cumple con los requerimientos esperados y además garantizar la satisfacción de los intereses de todas las partes implicadas. A menudo se le dice Testers indistintamente, pero es importante aclarar que esta palabra solo define la denominación de aquel que solo prueba el Software con un objetivo y documenta los resultados, así como informa de fallas, en cambio decir QA es un rol más global que incluye el testing como una de sus prácticas, el QA debe crear procedimientos y participar en la confección de estrategias de testing en varios niveles, digamos que si un QA solo hace testing en la capa de UI no está garantizando la calidad, aún si no hay fallas, ya que puede haber fallas que se presenten en producción y dependan de problemas directos en el código que se deploya, entonces no participar en el monitoreo de una estrategia por ejemplo de TDD o DevOps es no hacer un buen QA. Este rol es reponsable de comprender la lógica de negocio y validar el producto de Software a diferentes niveles. Debe controlar la realización de pruebas unitarias en el código fuente y de integración, luego a nivel de sistema (UI) y de aceptación de usuarios finales. Los QA deben conocer las fases del SDLC y plantear una estrategia de testing con cobertura de pruebas pertinentes e implicadas según cada etapa, además deben revisar estrictamente la documentación del producto y crear la nueva documentación que demuestre la calidad que se garantiza. Para las tareas de testing, el QA asegura que se creen pruebas de valor, para la ejecución, análisis y documentación, en trabajo cooperativo con los desarrolladores. Amedida se va integrando el código nuevo deben contribuir a la detección temprana de errores y la mejora continua del producto antes del despliegue y entrega final de la funcionalidad. Todo lo relativo a las prácticas del tester se desarrollará en las lecciones siguientes |
| 8-Desarrolladores de Operaciones (DevOps) | Este rol se encarga de programar toda la infraestructura para la integración de cada pieza de código que crean los desarrolladores, a medida va avanzando el proyecto, recordemos que se trata de un ciclo donde se va entregando un MVP pero no un producto de Software como un todo, por lo tanto se necesita crear un conjunto de operaciones que permitan garantizar esto, o sea que el código nuevo se integre, se testee para que no afecte el código que ya existe, se corrijan errores y se despliegue en el entorno de producción final. Los DevOps crean las metodologías programáticas que permitan garantizar y automatizar estas operaciones, para ello se encargan de la configuración de los servidores de CI/CD y su infraestructura. Este rol se encarga de configurar los diferentes ambientes del proyecto, los que conocemos como: Desarrollo, Pruebas ,Despliegue y Producción, esto se puede comprender mejor en el flujo de automatización de CI/CD. En el desarrollo de la infraestructura de los sistemas también se puede incluir el diseño y desarrollo de su arquitectura, que en algunas empresas estas tareas pueden ser asignadas a un DevOp o desmpeñadas por un rol específico como los Arquitectos de Software. Entre las tareas más importantes de este rol está la definición e implementción de la comunicación e intercambio de recursos entre las partes del sistema o los microservicios, por lo que se encargan de la implementación de las APIs y de la integración con otros sistemas. |
Los Desarrolladores "Full Stack"
Este rol es una nueva denominación para los desarrolladores, a partir de la necesidad de buscar recursos humanos que puedan desarrollar tanto el FrontEnd como el BackEnd, hay quienes dicen que por un tema de ahorro en el costo del trabajo humano, pero hay otras opiniones que defienden la necesidad de programadores integrales con capacidad global para desarrollar un Software completo, de aquí lo de "Full",para ello se necesitan desarrolladores con experiencia en ambos lados.
Entonces se dice Stack tecnológico, que en su traducción al español significa "pila" tecnológica, a la combinación de tecnologías usadas en el desarrollo de Software en un proyecto, o sea el dominio de varios lenguajes, metodologías y frameworks, Sistemas Operativos, Sistemas de Gestión de BD,etc., que puedan integrarse para el dasarrollo completo de un Software.
Un desarrollador full stack es considerado "un maestro del código" es como un arquitecto y un constructor que puede encargarse de todas las etapas y aspectos del desarrollo de un Software. Es un profesional con la capacidad de trabajar tanto en el lado del cliente como del lado del servidor, requiere una comprensión profunda y habilidades en los diversos elementos y lenguajes clave de programación, incluyendo arquitectura de Software, Bases de Datos, APIs, el manejo de IDEs, tecnologías de servicios en la nube para la configuración de servidores, la tecnología de contenedores y DevOps en general.
Ejemplos de Stack
LAMP: Linux, Apache, MySQL, PHP
MEAN: MongoDB, Express, Angular, Node.js
MERN: MongoDB, Express, React, Node.js
MEVN: MongoDB, Express, Vue, Node.js.

Prácticas en el SDLC: Control de Versiones (SCV)
El concepto de versiones se podría aplicar a las formas de crear un producto de manera general, digamos que si se hace un "zapato" con una marca personal, este va a iniciar con un diseño básico,luego se le van a ir agregando características, por lo que el producto va cambiando, se prueba se mejora y así en ciclos, entonces cada cambio ya sea por incorporar algo nuevo o por corregir un error, significa una versión nueva del zapato, hasta que se pone en venta, incluso a ese mismo zapato, se le pueden agregar nuevas características para lograr una mejor experiencia del consumidor, aquí tendríamos una versión nueva, pero si se quiere crear otro zapato para niños, por ejemplo, partiendo de el zapato básico, se necesita volver en el tiempo hasta esta primera versión,que debería estar documentada.
En el mundo del desarrollo de Software, se trabaja con el concepto de versiones, cómo decimos que en el Software se crea "escribiendo" un código por etapas y agregando cada nueva pieza de código, dónde además se puede debuguear (corregir errores en el código fuente) y volver a agregar nuevas piezas. Entonces, se puede usar la típica analogía de "una tesis de investigación",donde se planifica, se escribe,se revisa lo escrito, se cambia, se mejora, se revisa la lógica, la sintaxis, la estructura investigativa, etc., de cierta manera en el código podemos decir que tendría esta lógica de proceso, y si fuera una tesis grande van a trabajar varias personas agregando cambios, lo mismo que en un código que trabajan varios Devs. Siguiendo con el ejemplo de la tesis, todo el mundo sabe que en este proceso se crean varias versiones: tesis 1, tesis mejorada, tesis mejorada 2, tesis corregida, etc., hasta que se presenta el trabajo final.
En el desarrollo de un Software se necesita controlar y registrar las versiones que implican cambios, se necesita que todos trabajen en la misma versión y que los cambios se agreguen en la última versión, para que el trabajo vaya en avance y en concenso. Así se controla el historial de versiones de un Software, y si algún cambio pueda estar generando una falla, se podría volver a la versión donde se insertó y corregir desde allí el error para poder avanzar.

¿Qué tiene de particular el Control de las Versiones en un Software (SCV)?
Anteriormente en algunos temas, me he referido al desarrollo del Software, como la creación de un programa, escrito en en un código relativo a una forma de lenguaje, o sea escribir instrucciones en un lenguaje no humano, para organizar la lógica de funcionamiento: la máquina lee línea a línea el código y ejecuta el programa.
Este código se organiza para crear un "sistema" hay una entrada de información , un procesamiento de la información a modo de programa (instrucciones y pasos a modo de código) , y su transformación en un resultado deseado , que no es más que un funcionamiento esperado, o sea para que el Software tenga funcionalidades específicas.
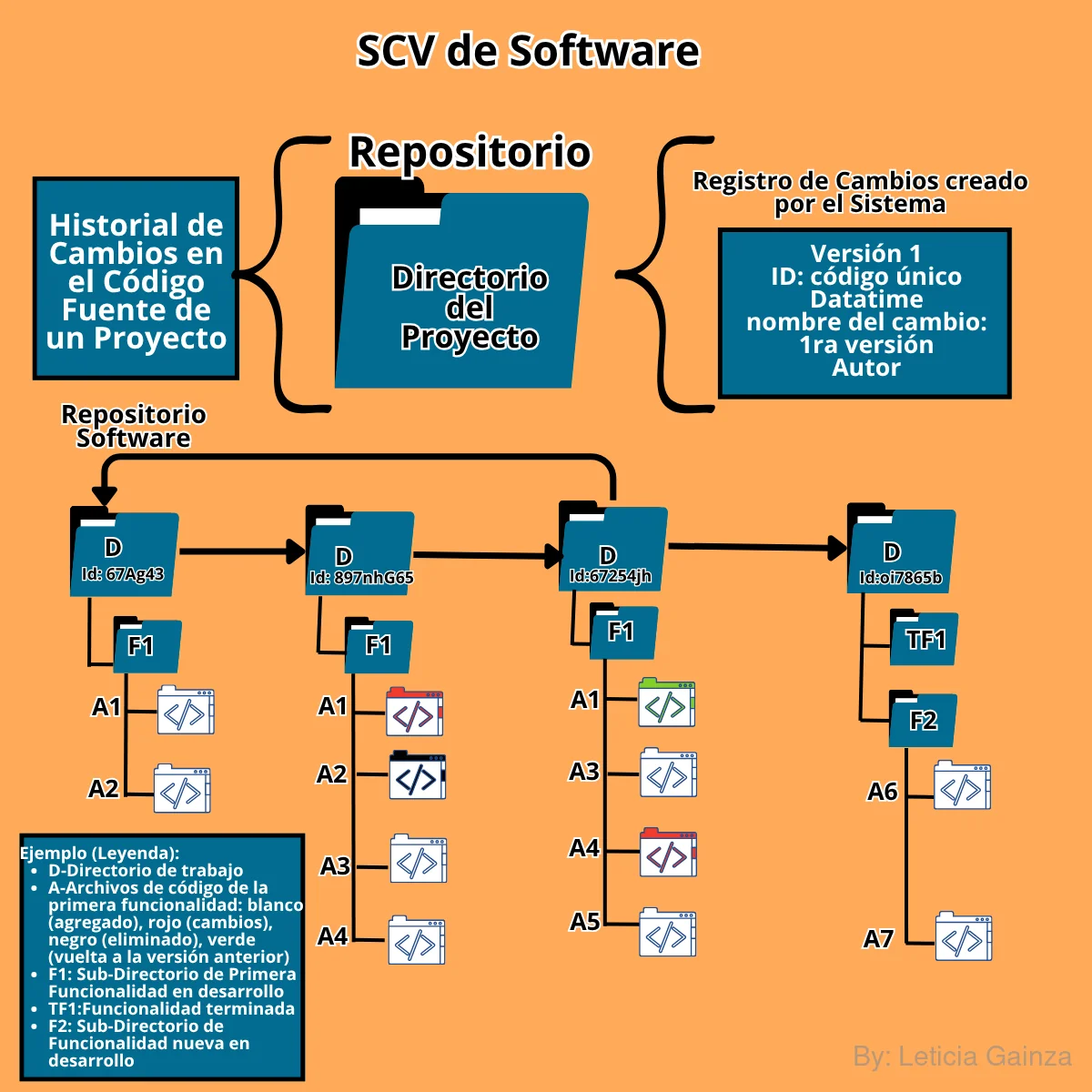
El Software se va a crear como una estructura de Directorios, tal como una carpeta y toda la información(programación) que se necesita para que las funcionalidades se ejecuten, se escribe y guarda en archivos de código.
La programación total de un Software no se crea completa ni perfecta de una vez, se particiona en módulos lógicos con el conjunto de operaciones específicas para un resultado, esto significa que se crea en partes, se ejecuta, se prueba y se unen las partes, en otras palabras, se va creando cada pieza de código e integrando, probando, se corrige, se vuelve a probar, se integra y si pasa todos estos filtros se despliega en el Software (funcionalidad que llega a los usuarios), hasta tener un producto que funcione de la forma deseada o MVP , estas integraciones entendidas cómo creaciones, correcciones, revisiones, se conciben como: versiones del código.
Por este motivo se necesita contar con un "Sistema" que procese cada cambio de código valiosos para el Software, y lo registre, guarde y controle como una versión del código, para su desarrollo incremental, su corrección de errores, su optimización, su mantenimiento y su entrega a los usuarios finales.
Entonces, un Sistema de Control de Versiones (SCV) o VCS es un sistema que permite registrar, guardar cambios y controlar versiones del Software, para esto organiza una estructura de datos conocida como Repositorio, esta establece las configuraciones de registro, mediante Id de versiones, nombres descriptivos, autor, fecha, hora, etc., para luego poder identificar y recuperar las versiones del Software, volver en el tiempo y compararlas de ser necesario. Estos sistemas se ejecutan a través de Softwares que tienen estas funcionalidades.
Otro punto importante para comprender esto es la necesidad de almacenar y recuperar el código, volviendo a la analogía de la tesis, cuando se escribe una tesis se guarda en el disco duro (SSD) en una máquina local, un archivo de código también se podría guardar allí, la tesis se puede guardar en un pendrive o memoria USB, por lo que se busca crear copias de seguridad, pero un código largo, complejo y pesado (Bytes) no se podría guardar, de la misma forma.
Es necesario poder almacenar y asegurar los archivos de código, si el disco duro se daña o se borra, no se podría recuperar, en el caso de una tesis perder todas sus copias es grave, imagina la magnitud de esta pérdida si se tratara de un Software. Por lo tanto se han creado programas que permiten guardar y recuperar las versiones del código y también guardarlo en un servidor remoto, donde ya no depende de un SSD local.
Los SCV, permite que los desarrolladores trabajen a la misma vez en la versión actual del Software, como antes he mencionado el Software se construye con código del lado del cliente, del lado del servidor, de la base de datos, etc, y por varios desarrolladores según su especialización, entonces, ¿cómo asegurar que todos trabajen a la misma vez en la última versión del Software?, aún si cada uno trabaja de manera independiente en su parte del código, pues los SCV permiten crear copias idénticas al proyecto original y sincronizar las versiones, así mientras se va atrabajando individualmente, cada desarrollador podrá integrar código nuevo, testearlo, y desplegarlo al proyecto de código final, sin que se afecten los demás desarrolladores. Luego si algún desarrollador va a insertar cambios depués de esta nueva versión desplegada,el sistema se encarga de sincronizar las versiones antes de desplegarlo, así se evita conflictos y se asegura una misma línea de tiempo de desarrollo en el historial de versiones del Software. El uso de los SCV tendrá sus prticularidades y reglas de uso, según la gestión del SDLC en cada equipo.
Por último los SCV son fundamentales para la arquitectura de Software en microservicios.
Nota: una versión de un SCV no es lo mismo que una versión de un Software, en el primer caso se refiere al control de cambios en archivos de código, en el segundo se refiere al lanzamiento de un Software total, con un conjunto de funcionalidades completas o la adición de nuevas funcionalidades finales, por ejemplo:
Software: Versión 1.0 del Software, Versión 2.0 del Software, etc.
SCV: Id:456uy-05/20-08:00-"Cambio del método cálculo factura en la Clase Factura"- Autor: Dev "Juan"-juan@gmail.com, etc.
Herramientas para SCV ó VCS
Reafirmando lo anterior : Se puede decir que un Sistema de Control de Versiones (VCS) es un software que registra el historial de cambios realizados en un archivo o conjunto de archivos a lo largo del tiempo, permitiendo recuperar versiones específicas, así como permite crear copias para trabajar en paralelo y asegura que todos los que trabajen en un proyecto tengan el mismo estado de la versión más reciente.
Es útil para otros tipos de archivo de texto en una computadora, no solo código fuente.
Usar un VCS permite regresar a versiones anteriores del proyecto, comparar cambios, ver quién modificó algo, y recuperar archivos fácilmente en caso de error o pérdida, ya sea usando una herramienta pagada o una de código abierto, a un bajo costo.
Existen diferentes tipos de sistemas de control de versiones:
| Sistemas de Control de Versiones Locales ó LVCS | Sistemas de Control de Versiones Centralizados ó CVCS | Sistemas de Control de Versiones Distribuidos ó DVCS |
|---|---|---|
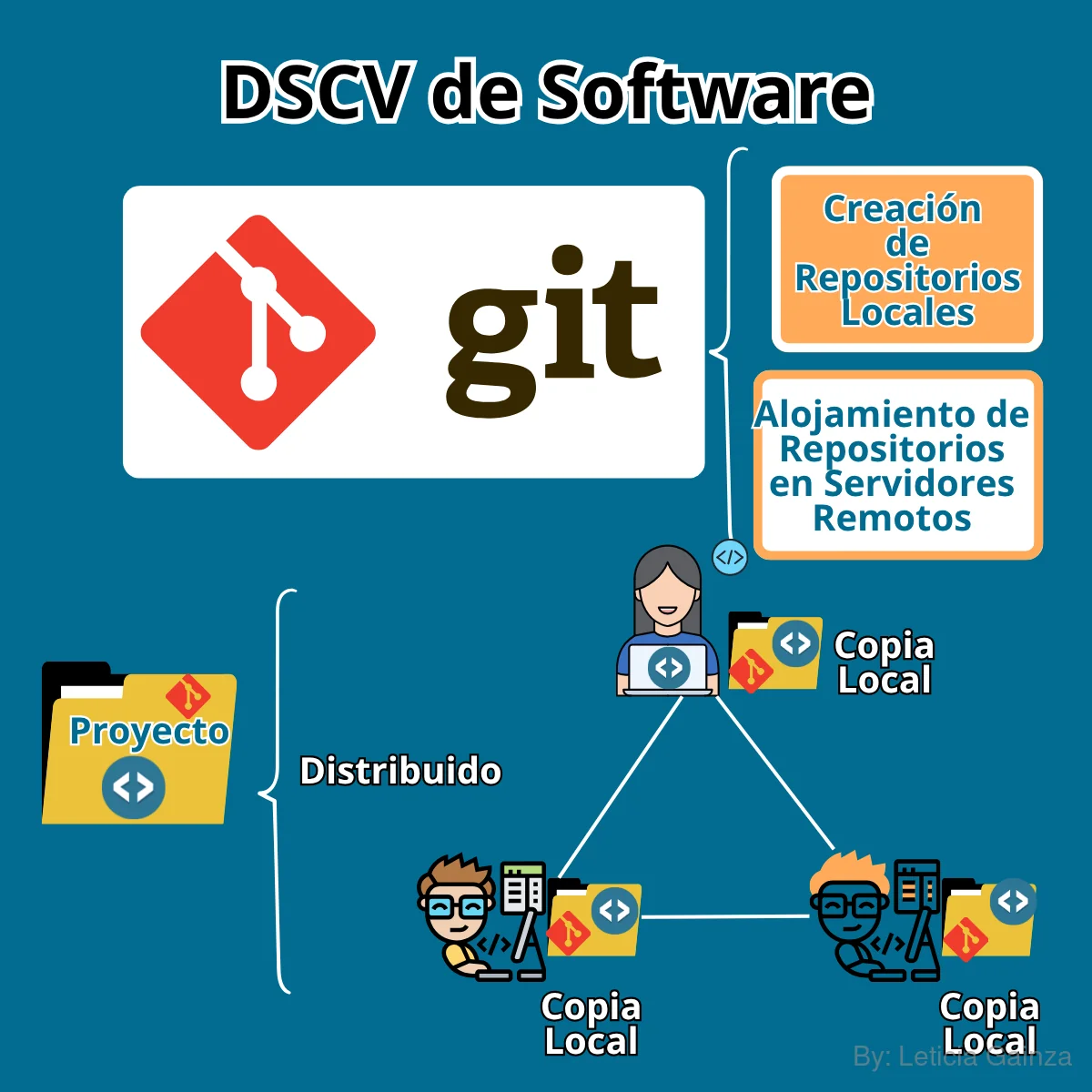
| Son los menos usados en la actualidad. En este método, las personas copiaban archivos a otros directorios (carpetas), a menudo indicando la fecha y hora. Herramientas como Sistema de Control de Revisiones (SCR) ó RCS, almacenaban conjuntos de parches (diferencias entre archivos) para recrear el estado de un archivo en cualquier momento. Este método era propenso a errores como sobrescribir archivos accidentalmente. | Estos sistemas tienen un único servidor central que contiene todos los archivos versionados, y los clientes descargan los archivos desde ese lugar, algunos ejemplos de CVCS son: Subversion y Perforce,. Aunque ofrecen ventajas como la visibilidad del trabajo de otros y control administrativo, su principal desventaja es que el servidor central es un punto único de fallo; si se cae, nadie puede colaborar ni guardar cambios, y si la base de datos se corrompe, se puede perder toda la información del proyecto. | Solucionan las limitaciones de los CVCS. En un DVCS los clientes no solo descargan la última copia de los archivos, sino que replican completamente el repositorio. Esto significa que cada clon es una copia completa de todos los datos. Algunos de estos Softwares son: Git, Mercurial, y Bazaar |
¿Qué es Git y porqué es tan popular como DVCS?
Primero comento que este Software fue creado por el desarrollador Linus Torvalds, quien es el mismo que creador del SO Linux, ya que trabajando en el propio desarrollo de este SO, estaba usando un SCV, pero que no cubría sus necesidades completamente, por lo cual trabajó en el desarrollo de Git, un sistema más eficiente para optimizar el trabajo de los desarrolladores.
Este fue el escenario que motivó a Linux a crear una herramienta de Softwre libre y de código abierto (open source), cualquiera lo puede instalar en su PC local y usarlo sin pagar por nada.
Git puede ser usado por toda persona que quiera colaborar en un proyecto. Para los QA además de ser importante entenderlo, también es útil para los que van a desarrollar el código sus sistemas de automatizaciones de pruebas, por lo que entender su uso y al menos las funcionalidades básicas es muy importante.
Git permite registrar un historial de cambios de un proyecto, para esto crea un "Repositorio", que es como designa el espacio donde almacena este historial, además permite acceder al repositorio de un proyecto alojado en un servidor remoto y clonar este con exactitud en un equipo local para trabajar con él. Cómo mencionaba antes Git como SCV permite:
Crear un Repositorio Local;
Permite almacenar el código fuente del proyecto en la computadora del desarrollador, lo que permite que tengan independencia y puedan trabajar sin necesidad de estar conectados a un servidor central o a Internet. Aporta velocidad ya que las operaciones son más rápidas al trabajar con la copia local del repositorio.
Alojar el Repositorio en un Servidor Remoto, Conectarse y Clonar:
Permite almacenar el código fuente del proyecto en un servidor externo o utilizar un servicio de alojamiento de repositorios administrados como GitHub, Bitbucket, GitLab. Esto permite que los desarrolladores tengan acceso a las versiones del código, independientemente de su ubicación geográfica. Además permite un tener un respaldo de código fuente del proyecto, ya que se puede clonar un repositorio remoto, y cada clon es un respaldo (backup) completo de todos los datos del proyecto.
Si el servidor remoto falla, puede restaurarse desde cualquiera de las copias en los clientes.
Guía explicativa para el uso de Git. Comandos para Flujo de Trabajo Local
Este flujo sirve para cualquier proyecto, incluso para las prácticas de Automatización QA. A estas instancias si eres un QA que ya autoamtiza comprenderlo es imprescindible, si por el contrario aún no has empezado te puede dar una visión estratégica sobre cómo se construye un Software ya que esta es una de las prácticas que se realizan en las etapas del SDLC, aprender a usarlo es sólo de práctica, acá muestro algunos comandos básicos, que tanto acá como en el sitio oficial de Git se pueden consultar cada vez que se necesiten, no es tanto memorizarlos (al menos los básicos sí) pero sí entender la lógica.
1-Instalación
Para empezar a usar Git es necesario instalar en su máquina local el Software Git, esto lo puedes hacer accediento a la web oficial de git https://git-scm.com/ y descargar el instalador correspondiente a tu SO, si es Linux y Mac ya lo traen integrados en las versiones recientes, puedes comprobar si estas instalado el Software Git, para esto se va a acceder a al programa "Terminal" que tienen todos los equipos, es una interfaz que permite ejecutar instrucciones de comandos a modo de líneas de instrucciones, emplea un lenguaje de comandos que es un lenguaje para el control de tareas en informática como shell o bash , digamos que es un espacio de trabajo donde se pueden escribir instrucciones a modo de scripts de comandos, desde el teclado, las operaciones típicas que realizan los scripts incluyen la manipulación de archivos, la ejecución de programas y la impresión de texto.
Conocer la terminal y familiarizarse con esta es muy importante, ya que muchos programas se pueden ejecutar de forma sencilla y más rápida, desde allí, solo conociendo los comandos, por ejemplo para un QA, si utiliza un programa que ejecute pruebas automatizadas, con usar un comando de terminal sobre la carpeta del proyecto, se puede tener un reporte de las pruebas ejecutadas, sin tener que abrir el programa.
Volviendo a Git y su instalación, se puede verificar si ya está en el SO de las siguientes maneras:
| Comando | Explicación | Ejemplo |
|---|---|---|
git --version ó git -v |
Lo primero que se hace para usar cada comando de Git es la palabra "git" en minúscula, seguida de un espacio y luego la instrucción: git --version |
Este es el primer comando que se va a usar para empezar a trabajar con Git. en este caso esta "-v" (simbolo -) ó "--version" (simbolo -)significa versión, por lo que se va a ver que versión del Software se encuentra instalada. Para usar este comando se va a buscar la "Terminal" del sistema operativo del equipo: Puede ser Barra de tareas del sistema/pulsar el Botón Inicio/Buscar/terminal- luego escribiendo git --version. Otra vía para acceder a la Terminal es usando el comando de teclado Ctrl + Alt + T (para Linux y Windows), o usando Tecla Windows + R luego escribir el nombre del programa "terminal" luego escribir el comando git --version |
Si no tienes el Software Git instalado, puedes instalarlo desde la web oficial de Git, cómo mencionaba antes y luego comprobar su instalación.
Si todo va bien, te saldrá información del número de la versión que tienes instalada.
De aquí en adelante puedes usar la terminal para interactuar con el Software Git y usar sus funcionalidades a través de sus comandos, ó por el cliente gráfico que ofrece el mismo Software, que se encuentra en la misma Web, se trata de una interfaz más visual y amigable para el usuario.
A fines de esta explicación y de la forma que aprendí a usar Git, lo haré directamente desde la terminal, usando la CLI de Git, que no son más que comandos que se escriben en la terminal para interactuar con el Software, donde el programa se ejecuta interpretando línea por linea, una vez que se escribe una instrucción, se aplica una tecla Enter esta acción indica al equipo que se ejecuta la instrucción. Una vez que se ejecuta el comando Git muestra a través de la terminal el resultado de la instrucción, en inglés, aunque es bastante intuitivo de leer la infomación que se muestra, una vez que se conoce la lógica del flujo de trabajo de Git y por supuesto sus funcionalidades.
Cabe aclarar que aún en la terminal, a pesar de no ser una UI gráfica, Git cuenta con un sistema de colores para mostrar la infromación y hasta opciones para graficar el historial de versiones usando decoradores.
Puedes escoger la vía que te resulte más amigable para usar Git.
En esta explicación también voy a usar otros comandos sobre el SO,que en dependencia del SO desde el que se ejecuten pueden variar, para mayor presición recoemiendo acceder a la documentación de CLI para Windows, Linux y Mac
Flujo de trabajo para un Proyecto Local
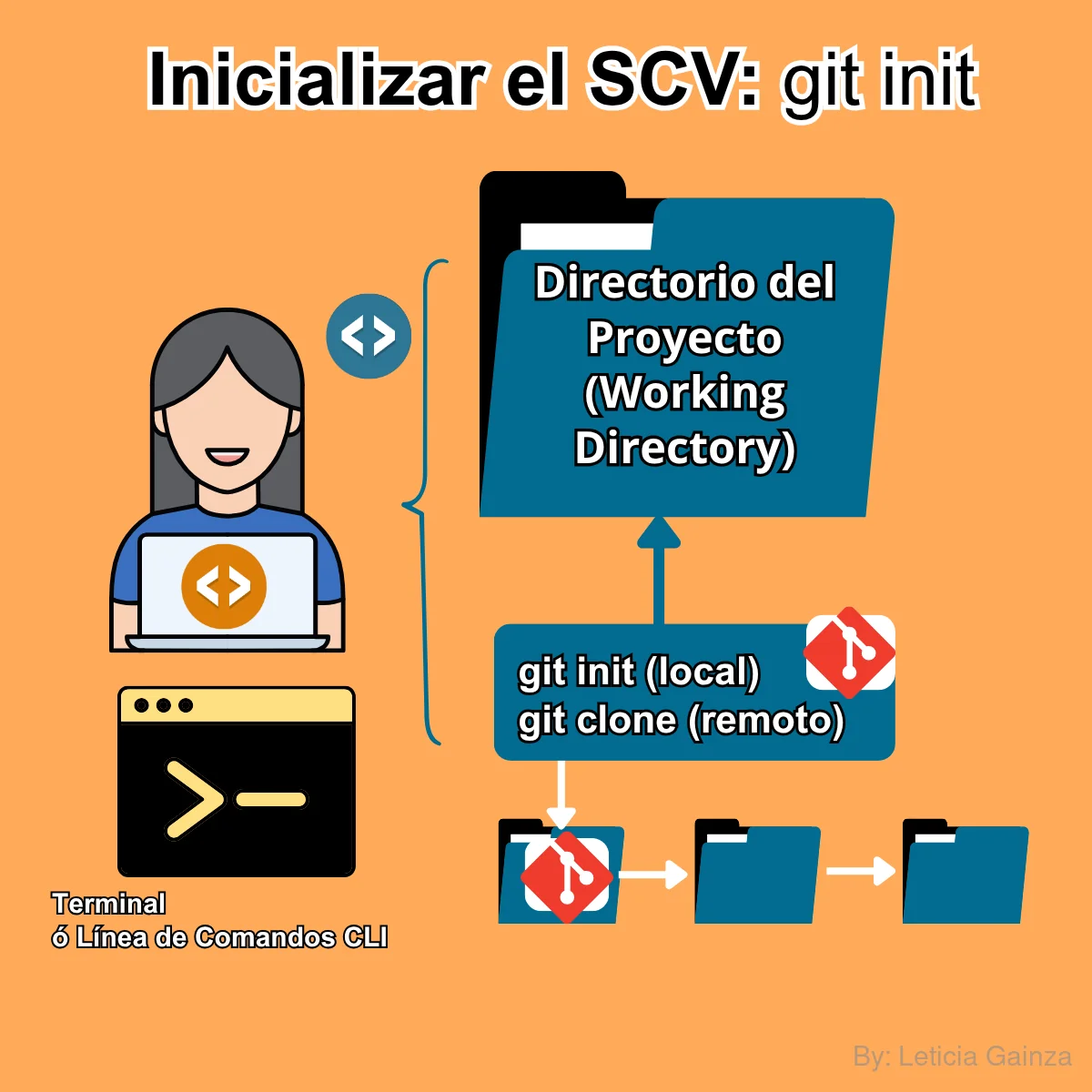
1er Comando: git init
Este comando se usa para Iniciar el Directorio de Trabajo (Working directory), significa que una vez definido en Proyecto en el que se van a controlar las versiones, se debe crear este espacio de trabajo donde Git va a almacenar las versiones del proyecto, o sea el "Repositorio", que de aquí en adelante llamaré: "Repo".
Para esto se define primero la carpeta (que de aquí en adelante llamaré Directorio) donde se va a alamacenar los archivos de código fuente del proyecto.
Es el espacio local donde se encuentran los archivos en los que el desarrollador está trabajando. Aquí vas a iniciar el repositorio, con el siguiente comando git init, de aquí en adelante se va a trabajar con el repositorio, ya que Git va a considerar este directorio con un repositorio asociado.
Nota: Git no es inherente a todos los Directorios porque puedes tener varios directorios de otros proyectos y no utilizar Git, por ende si quieres utilizar Git debes crear un repositorio en cada Directorio de Proyecto.
En esta explicación, usaré como ejemplo un Directorio de un Proyecto de Automatización de QA, no se trata de un Proyecto real, puesto que en la lección Testing Automatizado se ampliará un proyecto funcional, a instancias de este tema se usará para ir aplicando el flujo de comandos de Git desde la terminal.
Ejemplo de uso de git init:
| Comando | Explicación | Ejemplo |
|---|---|---|
dir |
Acceder a la Carpeta de espacio en memoria del SO. La Terminal muestra por defecto el directorio C, que es el Directorio de la raiz del SO, por lo que se usa este comando: dir (en Windows), para ver todos los directorios que contiene esta carpeta (en Mac y Linux el comando sería "ls") |
C:\Users> >dir |
cd "Usuario" |
Buscar el Directorio, este comando te lleva directamente a la carpeta, que deseas buscar, se coloca el nombre entre las comillas, se debe escribir el nombre tal y como es, sino no va a encontrar la carpeta | C:\Users> cd "Usuario" |
cd "Usuario" |
Crear un directorio nuevo, con el nombre entre comillas | C:\Users> mkdir "proyecto-test" |
dir |
Ver el contenido del Directorio, en este caso se verá la carpeta que se acaba de crear, vacía, porque no contiene ningun archivo. Se puede crear un archivo desde la misma terminal, buscar la carpeta en el escritorio del SO, abrirla con el explorador de archivos y crear el archivo directamente, en este caso lo haré con la CLI de Windows en el próximo comando que se mostrará | C:\Users\proyecto-test> dir |
touch "test1.py" |
Crear un archivo dentro del Directorio, este comando se usa para crear un archivo nuevo, con el nombre entre comillas, se puede usar tamabién este comando New-Item -Path . -Name "aprendo_git.py" -ItemType "File" en PowerShell |
C:\Users\proyecto-test> touch "test1.py" |
code . |
Abrir un editor de código o IDE, este comando se usa para abrir un editor de código, y ver el directorio actual "code espacio punto" | C:\Users\proyecto-test> code . |
cd .. |
Volver al Directorio Raíz del Proyecto, este comando se usa para volver al Directorio Raíz del Proyecto, ya que con el anterior, donde creamos el archivo, en CLI estamos parados en "test1.py", por ende se vuelve para el Directorio Raíz donde se va a crear el Repo. Dessde cualquier ubicación que se quiera ir hacia atrás se usa "cd .." hasta llegar al Directorio que se busca | C:\Users\proyecto-test\test1.py> cd .. |
git init |
Iniciar Git, este comando se usa para inicializar el repositorio en todos los archivos que están dentro de este proyecto, como es en local se usa "git init" pero si fuera para inciar un repositorio que ya estuviera iniciado en remoto se usaría un comando diferente como git clone |
C:\Users\proyecto-test> git init |
git status |
Ver el estado de tu repositorio, este comando se usa para ver el estado del repositorio, si hay algún cambio, si se ha añadido algo, por el momento solo se recibiría información de que no hay cambios, puesto que, ya el Repo iniciado contiene el único archivo que está vacío, cuando empecemos a trabajar en este, ya este comando mostraría que hay cambios, de igual forma si el archivo ya tuviera alguna información en el, se va a mostrar que no hay cambios, puesto que el Repo se inició en esa instancia con la información que ya tenia el archivo | C:\Users\proyecto-test> git status |
git config --global user.name "Tu Nombre" |
Configurar el usuario del SCV, este comando se usa para configurar el usuario del SCV, de forma global, o sea este es el nombre que va a aparecer en el historial de versiones en los repositorios que se creen, es útil cuando se trabaja con un repo remoto, cada usuario del SCV va a estar identificado, así se va a saber "quien hizo qué ó que desarrollador subió el cambio" | C:\Users\proyecto-test> git config --global user.name "Tu Nombre" |
git config --global user.email "exampe@email.com" |
Configurar el correo del SCV, este comando se usa para agregar el correo como parte de la configuración antes mencionada del SCV, esto se va a guardar en una carpeta que autogenera el Software Git, en una carpeta llamada ".git" dentro de la carpeta del proyecto | C:\Users\proyecto-test> git config --global user.email "example@email.com" |
clear |
Limpiar la terminal, este comando no es obligatorio, pero es buena práctica,se usa para limpiar la terminal o "clear", sirve para limpiar la pantalla de la terminal si hemos tenido muchas instrucciones, aporta ayuda en la visibilidad de la terminal | C:\Users\proyecto-test> clear |
git --help |
Buscar ayuda en la terminal, este comando se usa para ver la ayuda de los comandos de Git, o sea Git te va mostrar los comandos que utiliza, digamos que es una pequeña documentación de consulta, tambien puedes usar git -h que es lo mismo. |
C:\Users\proyecto-test> git --help |
Hasta aquí se inicializó el repositorio en el Directorio de Trabajo, pero como mencionaba antes, no se ha realizado ningún cambio, puesto que el archivo qu creamos está vacío y no no se ha agregado, ni eliminado ningún otro archivo.
2do Comando: git add
En el flujo de trabajo con Git, cada cambio que se registra en el Repo, primero se va a controlar en un espacio que se llama Área de preparación ( Stagin area )
Supongamos que en el Directorio "proyecto-test", se crearon 3 nuevos archivos: test2.py, test3.py y test4.py (el .py indica que Python es el lenguaje de programación del código fuente que van a contener los archivos, esto no afecta el uso de Git, ya que este SCV no distingue por tipos de lenguajes, por ende se aplica a todos los archivos de código), entonces, se necesita determinar si estos cambios se van a incluir en el historial del Repo, que en este caso por supuesto que sí, pero en otros casos se puede determinar cuando y qué cambios ya están listos para ser incluidos en el historial.
Ejemplo de uso de git add:
| Comando | Explicación | Ejemplo |
|---|---|---|
git add test2.py test3.py test4.py |
Añadir archivos a Stagin, este comando añade los archivos sobre los que se va a hacer cambios y formarán parte del historial de versiones | C:\Users\user\proyecto-test> git add test2.py test3.py test4.py |
git add . |
Añadir todos los archivos a Stagin este comando es para agregar todos los archivos sin distinguir, para esto se usa "git add espacio." | C:\Users\user\proyecto-test> git add . |
git status |
Ver el estado de tu repositorio, antes se explicaba este comando, pero es una buena práctica que se usa para ir revisando el estado del repositorio, antes de crear versiones | C:\Users\user\proyecto-test> git status |
git diff --staged |
Ver el contenido de la Área de preparación, este comando se usa para ver el contenido de la Área de preparación, así permite ver que se ha colocado nuevo en relación a la ultima versión antes de crear una nueva, en este caso no contendria nada porque ya se agregaron los 3 archivos y no se ha realizado ningun cambio | C:\Users\user\proyecto-test> git diff --staged |
git diff |
Ver el contenido de la Área de preparación, este comando se usa para ver el contenido de la Área de preparación | C:\Users\user\proyecto-test> git diff |
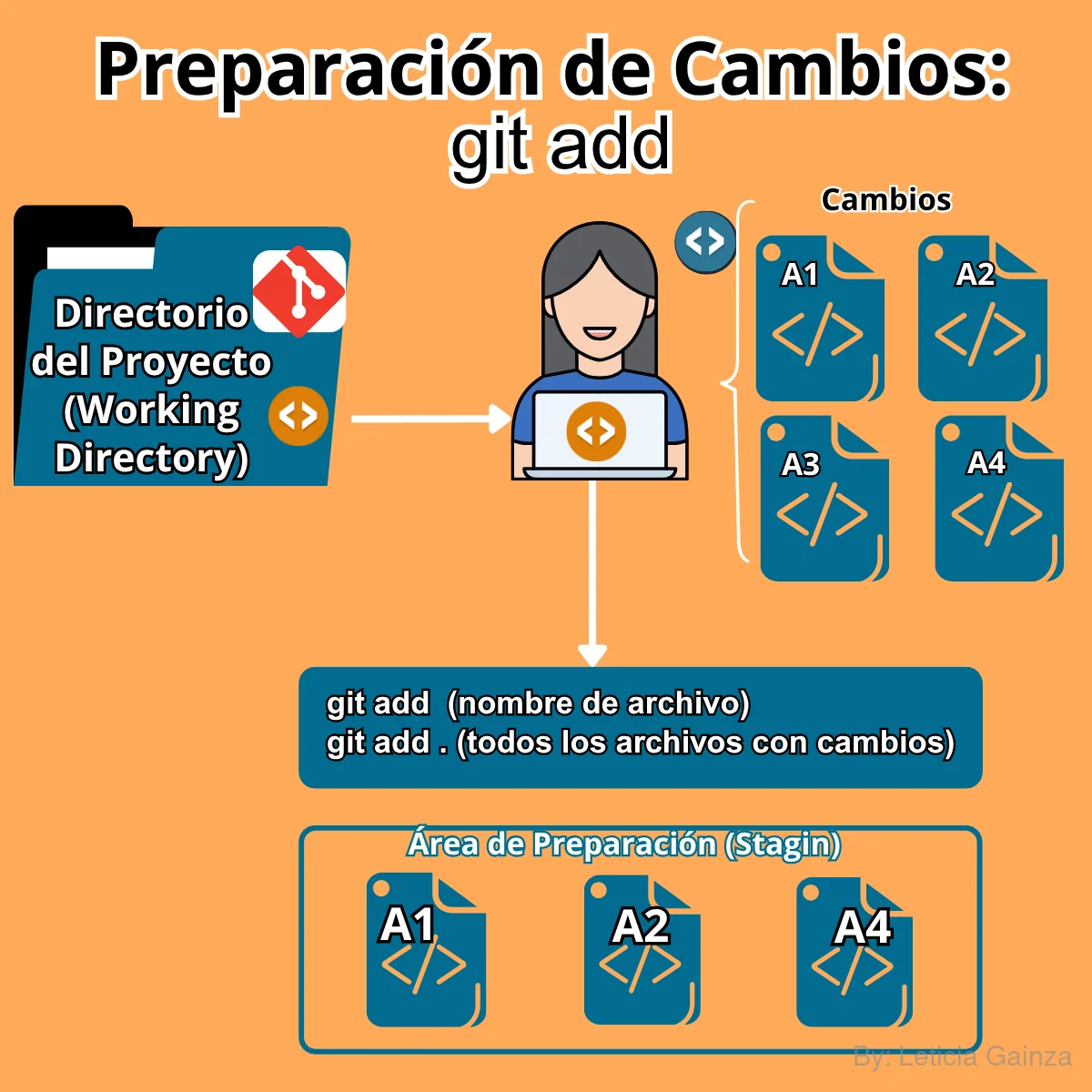
Todo cambio que se realice en un archivo y se quiera incluir en las versiones primero se debe añadir a Stagin, si se han realizado cambios pero no se está seguro de haberlos registrado, se puede usar este comando git status, antes mencionaba que git usaba colores para mostrar el estado del repositorio, ahora vamos a ver los archivos que se han modificado, aparecen en color rojo.
3er Comando: git commit
Este comando es el que permite crear las versiones de los cambios, que se van a registrar en el historial, hasta el momento solo se habían añadido los cambios a un área de espera, pero aún no se trata de versiones, con esto Git asegura que un grupo de cambios guardados serán convertidos en una nueva instancia del proyecto, o sea una nueva versión.
Este comando es el que va a permitir crear el Historial de versiones (Commit)
Una vez que se han agregado los archivos a la Área de preparación (Stage), ahora se puede hacer el Commit, por lo que lo primero es condición para lo segundo, cada cambio que siga este flujo se irá agregando en el historial de versiones.
En algunas explicaciones se dice, que el Commit es como hacer una foto, porque el sistema de Git, guarda el cambio y autogenera un identificador, a este se le conoce como el hash, que en otras palabras, es una secuencia de caracteres únicos, que va a identificar a cada commit, por lo que cada foto va a ser única, así se puede detectar cada versión guardada con cada cambio.
A través de la funcionalidad de "Commit" el sistema, además del hash, también agrega en el registro de la versión del cambio nuevo: la fecha, hora y los datos de la configuración del usuario y por último el mensaje que contenía el cambio, digamos que esto se puede ver como el "nombre del commit", esto hace más sencillo la tarea de identificar las versiones, así los que trabajan en un proyecto pueden ver de que se trató esa versión guardada.
Ejemplo de uso de git commit:
| Comando | Explicación | Ejemplo |
|---|---|---|
git status |
Ver el estado del Repo, para asegurar que los cambios estén listos para ser incluidos en el historial de versiones | C:\Users\user\proyecto-test> git status |
git commit -m "Primer Commit" |
Crear el Commit, este comando se usa para guardar los cambios, o sea regsitrar una nueva versión, se agrega -m , seguido del espacio y entre comillas se coloca un mensaje, este mensaje se usa para identificar la nueva versión, siempre descriptivo, corto y claro, que indique de que se trata esta nueva versión, por ejemplo "Corrección de error tags href en el archivo index.html" | C:\Users\user\proyecto-test> git commit -m "Primer Commit" |
git status |
Ver el estado del Repositorio, este comando es opcional pero es una buena práctica para confirmar los resultados de la ejecución, en este caso Git informará que no hay cambios pendientes a comitear, en inglés "nothing to commit", en su lugar si hubiera algo pendiente indicará el archivo y además en color verde | C:\Users\user\proyecto-test> git status |
git log |
Ver el contenido del Historial (log) de versiones, este comando se usa para ver el contenido del historial de versiones, ofrece un histórico de todos los commit que se han hecho, log es historial, log va a mostrar cada commit con varios datos, incluyendo la cadena larga de caracteres del Id (hash) | C:\Users\proyecto-test> git log |
git log --oneline |
Ver el Historial (log) con otra representación gráfica, este comando se usa para ver el contenido del historial en una sola línea, reduce el hash, presenta solo el mensaje que identifica cada commit, --oneline sería un decorador | C:\Users\proyecto-test> git log --oneline |
git log --graph |
Ver el contenido del historial con otra representación gráfica más visual, esto muestra el historial como una gráfica o rama, se usa el decorador graph, para ver la información graficada | C:\Users\proyecto-test> git log --graph |
git log --graph --pretty=oneline |
Usar otros decoradores del log, con esto voy a ver el historial más visual, graficado pero en una sola linea por commit | C:\Users\proyecto-test> git log git log --graph --pretty=oneline |
git config --global alias.proyecto_pruebas1 "log --graph --pretty=oneline" |
Usar un alias para el log, esto es para crear un alias del log, con los decoradors que queremos, así no hay que colocar cada vez que se necesite un decorador para ver el log, en lugar de esto la representación se guarda con un alias | C:\Users\proyecto-test> git config --global alias.proyecto_pruebas1 "log --graph --pretty=oneline" |
git proyecto_pruebas1 |
Ver el historial (log) usando el alias, con esto voy a ver el historial mas visual, graficado pero en una sola línea por commit | C:\Users\proyecto-test> git proyecto_pruebas1 |
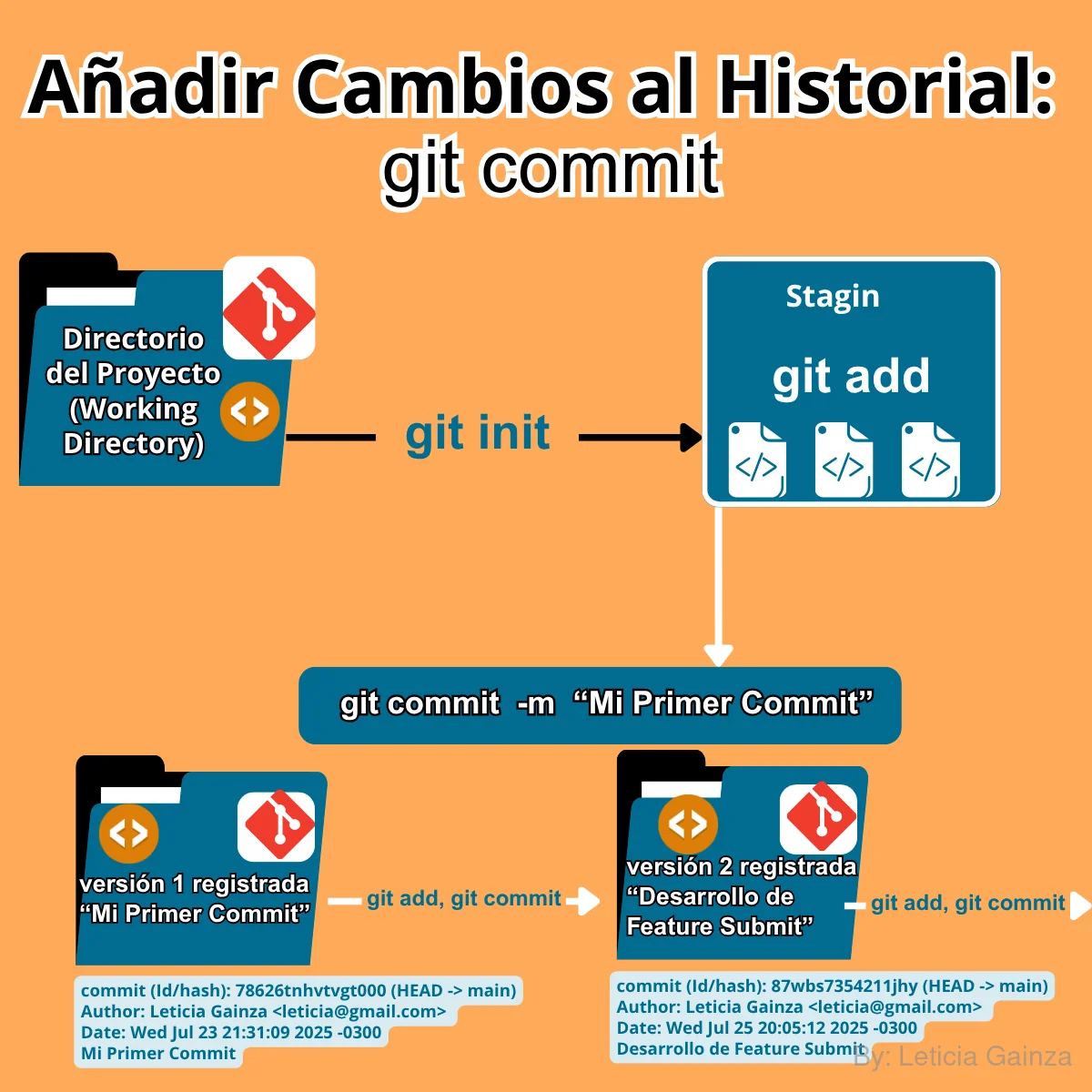
Todo cambio que se quiera guardar como una nueva versión debe convertirse en un Commit, cada vez que se haga un cambio sea algo nuevo o corrección de error , se va a repetir este ciclo:
Resumen del flujo de trabajo:
- 1- Inicializar el repositorio: git init
- 2- Agregar los archivos al Área de Stage: git add
- 3- Ver el estado del repositorio (si hay cambios pendientes a añadir o a comitear): git status
- 4- Crear el Commit: git commit -m "Mensaje descriptivo del Commit"
- 5- Ver el contenido del historial de versiones: git log
El uso de las Ramas para los SCV
Hasta ahora hemos visto el flujo de trabajo habitual de Git, en el proyecto principal, ahora voy a hablar de las ramas y como se trabaja con ellas, que es una de las funcionalidades valiosas del SCV Git.
4to Comando: git branch
En el flujo anterior se creó un Directorio y un Repositorio en este, que al ser el primero y único, Git lo identifica como la rama principal de trabajo, digamos que el proyecto final original, así por defecto Git lo empieza a nombrar: master.
Si se hace un git status, en la primera línea de información que se muestra en la terminal es: "On branch master", con este mensaje se puede confirmar que los cambios se estan agregando directamente en el Repositorio Principal y único que hasta el momento hay, pero si necesitamos trabajar cambios que aún no se quieren agregar en este, debemos crear una copia de este y poder trabajar ahí sin afectar el Repositorio Principal, si se realiza esta acción, ya el mensaje comentado antes cambia, por ejemplo a esta copia le voy a llamar "otro_repo", y si estuviera trabajando en esta copia y hacemos un git status veríamos que el mensaje anterior que muestra la terminal ahora es: "On branch otro_repo".
Esto de crear una copia más allá de un nombre, significa que podemos hacer uso de un de las funcionalidades de Git, que es la creación de Ramas, en inglés Branch, esto nos va a permitir trabajar en paralelo en distintos proyectos, sin afectar el principal. Cuando se inicializa un Repositorio , por defecto el sistema crea una rama principal a la que llama "master" (por eso en el primer mensaje comentado antes se dice "On branch master"), luego usando el comando para crear ramas, el sistema permite crear copias idénticas del Repositorio Principal.
¿Por qué usar la cración de Ramas?, pues con esta funcionalidad se puede dividir el trabajo y aislarlo sin afectar el proyecto principal, además permite que se trabaje en paralelo en distintas partes del proyecto, lo que mejora la eficiencia de trabajo, si en un proyecto se tienen varias funcionalidades y se va desarrollando cada una por etapas, se pueden crear varias ramas para trabajar en los módulos relativos a las features, cada desarrollador podría trabajar en una rama diferente.
Si usamos esta "Branch" para prácticas de QA por ejemplo, imaginemos que tenemos un proyecto de desarrollo de un sistema de automatización llamado "Proyecto Prueba QA" con 4 archivos principales, este sería el Repositorio Principal que se inicializa, luego se necesita ir agregando funcionalidades al sistema sin afectar el Repositorio Principal, además van a trabajar varios QA en el proyecto, por lo tanto el uso de ramas favorece el flujo de trabajo. Se puede crear primero una rama de Desarrollo, en la que se irá agregando e integrando cada funcionalidad, y luego desplegarla en el Repositorio Principal. En paralelo a esta rama se van crear otras ramas para cada funcionalidad que se desarrollará, por ejemplo "Escenarios Negativos", "Escenarios Positivos", "Escenarios de Regresión", etc. Cada QA puede trabajar en la rama asignada e ir registrando sus cambios en la rama correspondiente, nada de lo que se haga en estas va a afectar a la rama principal, ni a las paralelas, una vez que se haya terminado el trabajo en cada rama, se puede incorporar en la rama principal y luego eliminar la rama copia para evitar problemas y así todos los colaboradores van a seguir desde la misma versión general actualizada.
Yo, en particular para explicar la lógica de las Ramas mejor, planteo la analogía de master como si fuera un árbol, al que le van a ir creciendo varias ramas a medida pasa el tiempo, cada rama va a tener la misma información biológica del árbol, las que además luego de crecer y cumplir su función van a caer, pues en un Proyecto el Repo master va a tener varias ramas para trabajar, todas con la misma información del tronco principal.
Cabe aclarar algo, que aunque se pueda agregar cambios directamente en master no estaría mal, de hecho, estaría bien si es un proyecto pequeño, solo local incluso, en realidad va a depender de la magnitud, complejidad y valor del proyecto y por supuesto de quienes lo trabajen. Pero si se trata de un proyecto grande, con muchos archivos, muchos commits, muchos cambios, como se trabaja en la realidad, en el trabajo colaborativo de SDLC, no es bueno trabajar directamente en master, porque sino, cada cambio va directo a master, sin comprobarlo, sin poder testearlo, e incluso aplicar una práctica de revisión conjunta por todo el grupo de desarrolladores, conocida como Code Review. Además los Dev suelen trabajar por funcionalidad y esta las subdividen en módulos, por lo que es bueno crear ramas, para trabajar en un módulo en particular, y luego unirlo a toda la funcionalidad, después testearlo y revisarlo, para desplegarlo al proyecto final.
En resumen: Las Ramas son copias idénticas del proyecto principal, que permiten trabajar en paralelo, son trabajos temporales, cosas que se van haciendo, es recomendable crear las ramas y eliminarlas una vez que ya se ha completado el trabajo.
Cuando aborde los repos remotos esto se verá mejor representado.
Ejemplo de uso de git branch:
| Comando | Explicación | Ejemplo |
|---|---|---|
git branch -m main |
Renombrar la rama principal, primero con este comando, vamos a renombrar master, llamándole "main",por convención de la comunidad de desarrolladores le suelen llamar así | C:\Users\proyecto-test> git branch -m main |
git branch -a |
Comprobar las ramas, este comando se usa para ver las ramas, -a es un decorador, se usa también para ver todas las ramas incluyendo y las ramas remotas, así se puede ver que ramas se tienen en el repositorio, además se podrá ver el cambio del nombre que se le hizo a master- cambiada a main, también se puede hacer un "git status" y se puede ver que el nombre cambió | C:\Users\proyecto-test> git branch -a |
git branch test_negativos |
Crear la nueva rama, este comando permite crear la nueva rama, se agrega el nombre de la rama después de branch en minúscula | C:\Users\proyecto-test> git branch test_negativos |
git log --oneline --graph |
Ver las ramas en el historial (log), cuando ejecutamos este comando vemos las ramas pero encabezando la información, vamos a ver esto: (HEAD -> main,test_negativos1) donde HEAD indica en que rama se está trabajando en ese momento, en este caso indica que está en main, porque creamos la otra rama pero no hemos cambiado la posición de HEAD (desde donde estamos situados trabajando) | C:\Users\proyecto-test> git log --oneline --graph |
git switch test_negativos |
Cambiar de ramas, este comando se usa para cambiar de rama, ahora si hacemos el log vemos que HEAD cambia de posición, he indica que los cambios se están haciendo en esta rama | C:\Users\proyecto-test> git switch test_negativos |
git add ., git commit -m "estructura para test negativos" |
Agregar Cambios y comitear, se realiza todo el flujo de agregar cambios y comitear para registrar todos los cambios que se realizan en la rama, cada comando se ejecuta separadamente a modo de línea | C:\Users\proyecto-test> git add ., git commit -m "estructura para test negativos" |
git checkout test_negativo1.py |
Agregar cambios y volver en el tiempo, si he hecho modificaciones en el código y quiero volver a última versión que se había comiteado (guardado) de los archivos que tuvieron los cambios, se usa el comando checkout con el nombre del archivo | C:\Users\proyecto-test> git checkout tes_negativo1.py |
git checkout 4c4da34 |
Hacer Versiones y volver en el tiempo, Si he hecho varios commit pero quiero volver en el tiempo a trabajar una versión específica, puedo hacer un git log, que recordemos que en cada commit se deja un mensaje, así se puede ver el commit que necesitamos y solo copiar y pegar el hash | C:\Users\proyecto-test> git checkout 4c4da34 |
git reset |
Volver al último commit hecho, este comando se usa para volver al último commit hecho,esto si quiero volver para atrás a la última fotografía, o la modificación que tenía | C:\Users\proyecto-test> git reset |
git reset --hard 5c5da34 |
Volver a un commit específico y eliminar todos los commit posteriores, este comando es de mucha responsabilidad porque se carga todos los commit, o sea todas las versiones que se registraron después del commit al que se quería volver | C:\Users\proyecto-test> git reset --hard 5c5da34 |
git reflog |
Ver el Historial (log) de cambios completo, este comando permite ver el historial completo, aún con los commits que se hayan eliminado, porque si antes estuvo comiteado el Software lo guarda, todo esto depende del archivo .git, que Git crea en la carpeta del proyecto | C:\Users\proyecto-test> git reflog |
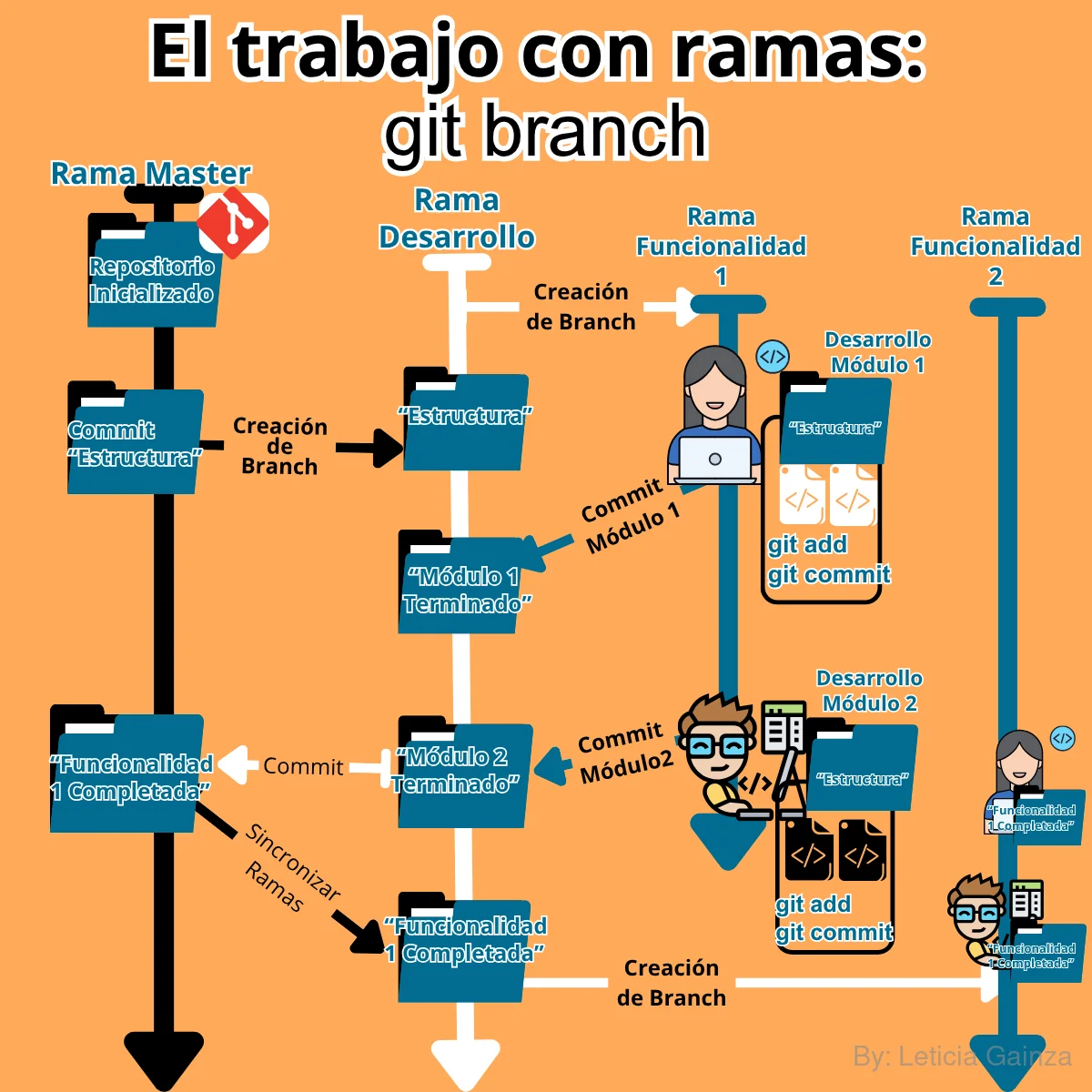
5to Comando: git merge
Como mencionaba antes,las ramas son útiles para trabajar en paralelo, pero una vez que se termina de cumplir el objetivo para el que se crearon se deben unir los cambios a la rama "main", para tener los últimos cambios en el Proyecto Principal y continuar trabajando desde esa versión.
En los flujos anteriores se fueron comiteando los cambios en la rama que se trabajaba, ahora estos se vana desplegar hacia la rama main, a esta acción se le dice merge. Esto se realiza a trvés del comando "git merge". El flujo de Git ya va sentando las bases para automatizar la integración de código nuevo desde las acciones de commit (aunque esto es más amplio puesto que hay otras acciones en remoto) y con el merge ya se habla de despliegue, puesto que en resumen se trata de agregar los cambios creados en paralelo a la rama principal que es la que contiene el código de producción, esto es relativo y básico para el flujo de CI/CD que se abordará más adelante.
Ejemplo de uso de git merge:
| Comando | Explicación | Ejemplo |
|---|---|---|
git diff main |
Revisar si hay cambios en la rama con la que se quiere mergear(unir), con este comando aseguramos que no se haya insertado nada en la rama principal, puesto que como se trabaja en paralelo, si en main se hubieran hecho commit ya sea de forma directa o indirecta por otra rama que se hubiera creado en paralelo, se perderian esos cambios mientras se trabajaba en la rama que creamos para trabajar y que se va a mergear, además informa cuáles son los archivos que se han modificado y están diferentes, esto ayuda a prever conflictos, si hay alguno, Git no va a permitir unir las ramas hasta que no se resuelvan las difenerencias, o sea los conflictos | C:\Users\proyecto-test> git diff main |
git merge test_negativos |
Unir las ramas, hacer el merge, este comando se usa para unir las ramas, desde la rama donde se estaba trabajando hacia la que se quiere unir, en este caso a main. | C:\Users\proyecto-test> git merge test_negativos |
git switch main |
Cambiar hacia la rama donde se hizo el merge | C:\Users\proyecto-test> git switch main |
git status |
Revisar el estado del Repositorio, podemos comprobar que todo se ha integrado correctamente y vemos el HEAD que se ha cambiado a la rama que nos hemos movido antes, en este caso a main | C:\Users\proyecto-test> git status |
git branch -d (nombre de la rama) |
Eliminar la rama, este comando se usa para eliminar la rama, que ya no se va a seguir trabajando y ya se culminó, esto son buenas prácticas | C:\Users\proyecto-test> git branch -d test_negativos |
git tag (nombre de la versión) |
Identificar una versión especifica, este comando se usa para identificar las versiones, se usa el comando tag, y el nombre de la versión que se tiene hasta ese commit | C:\Users\proyecto-test> git tag version1 |
Guía explicativa para el uso de Git. Comandos para Flujo de Trabajo Remoto
Hasta el momento solo hemos creado un Repositorio local, pero, necesitamos colocar nuestro proyecto en un repositorio remoto, para tener una copia de seguridad en un servidor externo. Cómo explicaba antes Git permite alojar el Proyecto en servidores externos, para ello se usan plataformas como GitLab, Bitbucket, GitHub, etc. Estos son tecnologías creados para alojar proyectos y favorecer el trabajo colaborativo, entre las personas que trabajan en un mismo proyecto, en principio tendrían funcionalidades similares a un SCV Distribuido como lo es Git, además comparten permiten funcionalidades muy similares entre sí como la colaboración en proyectos de código abierto, la posibilidad de Repositorios públicos o privados (el límite y los beneficios son específicos de cada tecnología), las revisiones de cambios, los flujos de integración continua y despliegue continuo, contienen diferencias más enfocadas a las features (características) que poseen.
Hablemos de GitHub
Para ejemplificar un SCVD Remoto se podría usar cualquiera de las plataformas mencionadas antes, pero en esta explicación usaré GitHub, que es muy popular en la comunidad de desarrolladores y es gratuita.
Github en su esencia es un servidor de alojamiento de Repositorios de Software, que permite la integración con las funcionalidades de Git. El éxito de GitHub es que además de permitir el alojamiento de los Repositorios, ofrece otras funcionalidades como herramientas para CI/CD y otras herramientas de colaboración, además es una Red Social, en principio, igual que Twitter, Facebook, Instagram, etc, pero con la peculiaridad de que se contenido que se comparte es relativo al área de tecnología, en especial en el area de desarrollo de Software.
Puedes seguir el trabajo de otros desarrolladores, incluso clonar un repositorio de proyectos que ya existen y adaptarlo a tus necesidades, además de poder crear tus propios repositorios, y también en esta plataforma se coloca documentación de valor para el uso de muchas tecnologías.
Para empezar a usar GitHub, recomiendo, buscar en el Navegador la web oficial de GitHub https://github.com y crear un perfil, luego crear tu primer repositorio, que digamos, contendrá información general sobre ti, a que te dedicas, tus proyectos, básicamente sería como crear un perfil.
Luego GitHub proporciona una guía muy intuitiva para que conocer sus funcionalidades,de todas fomas recomiendo los tutoriales de GitHub para familiarizarte con su uso.
Una vez creado el perfil, se accede a la opción de crear un Repositorio nuevo y GitHub proporciona un espacio para colocar tu proyecto ahí, pero antes te va a mostrar un mensaje, que te dice con una serie de comandos si vas a crear un repositorio nuevo en GitHub, o si quieres usar un repositorio existente en local y colocarlo en GitHub, o sea sincronizarlo y te va a mostrar una URL,que debes copiar y pegar en la terminal para que tu repo local se aloje en ese espacio.
6to Comando: git remote
| Comando | Explicación | Ejemplo |
|---|---|---|
git remote add origin https://github.com/tu-user/proyecto-test.git |
Crear el repositorio remoto, este comando se usa para crear el repositorio remoto, con el nombre origin, o sea que origin es como se va a llamar en GitHub tu rama main y la URL del repositorio remoto. | C:\Users\proyecto-test> git remote add origin https://github.com/tu-user/proyecto-test.git |
git branch -M main |
Sincronizar cambios,este comando se usa para indicar que la rama main del repositorio local se va a sincronizar con la rama main del repositorio remoto | C:\Users\proyecto-test> git branch -M main |
git push -u origin main |
Enviar el Repositorio local a GitHub,este comando se usa para enviar el repositorio local a GitHub, con "-u" se indica se indica una relación de seguimiento entre el repositorio local y remoto. | C:\Users\proyecto-test> git push -u origin main |
Luego todo el repo que se hizo en local se va a sincronizar con el remoto y listo.
Después se continúa trabajando en el repo local y se sigue haciendo el mismo flujo hasta los commit, luego se va a sincronizar estos cambios en el repo remoto, repitiendo el comando anterior.
Ahora supongamos que alguien más está trabajando en el Repositorio remoto y es parte de tu equipo de QA, además tiene los accesos para hacer cambios en el repo, estos accesos se configuran en GitHub y dependen de como se configuraron de los niveles de organización y autorización en tu equipo.
Imaginemos este otro escenario:, supongamos que hay varios QA trabajando en un proyecto de Automatización creado por el Líder de QA, si este organiza tareas diferentes para cada integrante del equipo, se van a insertar cambios en paralelo, por lo que se podrá empezar a trabajar en una rama, mientras otros van agregando cambios en el Repo remoto, en este caso que se podría hacer?.
Comandos para Actualizar y Enviar los cambios: git pull y git push
| Comando | Explicación | Ejemplo |
|---|---|---|
git fetch |
Ver cambios en el repo remoto, este comando se usa para ver los cambios en el repo remoto, te permite ver desde main en local los nuevos cambios que se hayan incluido en remoto, digamos que es como un "diff" que te permite ver archivos que hayan cambiado y especificaciones | C:\Users\proyecto-test> git fetch |
git pull |
Actualizar cambios en tu repo local, te indica lo que puedes hacer con tu repo local, respecto al remoto, o sea si en el remoto hubo cambios, y no sincronizaste tu repo local con el remoto, te indica que primero debes sincronizar tu repo con el remoto con "merge" para tener la última versión y luego poder enviar tus cambios, esto detecta si hay conflictos de versiones, en caso de que no haya conflictos, el sistema indica que tod está listo para enviar tus cambios, así el SCV se asegura que todos los implicados tengan la ultima versión a la misma vez | C:\Users\proyecto-test> git pull |
git merge origin/main |
Sincronizar tu repo local con el remoto, con este comando, ya se puede traer a local los nuevos commit que estén en Github y evitar conflictos en local con el remoto | C:\Users\proyecto-test> git merge origin/main |
git push |
Enviar los cambios al repo remoto, este comando se usa para enviar los cambios al repo remoto, pero antes te debes asegurar que fueron añadidos y comiteados en local, que se hizo un pull con remoto y no hay conflictos en local | C:\Users\proyecto-test> git push |
Trabajo Colaborativo: git clone y Pull Request
En el SDLC para trabajar en un proyecto colaborativo, primero se organizan la estructura del Repo en remoto, cuantas ramas va a tener, que permisos se van a dar, etc.
Según la oganización un Líder Tecnológico ó TL, va a ser el responsable de la creación del Repo en remoto y le da acceso a otros desarrolladores, puede ser compartiendo el link, ó a través de un token de acceso, etc.
Siguiendo con el ejemplo de un Proyecto de Automatización de QA, el Líder de QA va a ser el responsable de la creación del Repo en remoto, con el permiso de "push" y "pull" para los desarrolladores de QA.
Supongamos que el Repositorio de un Proyecto ya está alojado en Github y en el que vas a empezar a trabajar, teniendo los permisos adecuados, en Github se puede ver una opción que dice "branch", esta funcionalidad permite ver las ramas, así que se debería buscar la rama asignada para trabajar, que por buenas prácticas nunca sería la rama principal, en los proyectos de desarrollo habituales se crean ramas como: "develop", "test", "staging", "production", etc, los nombres de las ramas y la cantidades es relativo a como se organiza cada equipo.
Ejemplo del Flujo de Trabajo Colaborativo en Remoto
| Comandos | Explicación | Ejemplo |
|---|---|---|
git clone url |
Acceder a un Repositorio Remoto, en una rama,con permisos para trabajar, con este comando puedes crear en tu espacio local una copia del repositorio remoto,idéntica | C:\Users\proyecto-test> git clone https://github.com/tu-user/proyecto-test.git |
git push |
Hacer cambios en la rama y enviarlos a remoto, antes de ejecutar este comando debes hacer todo el flujo de Git, git add, git commit -m "mensaje", git pull, git merge origin/main | C:\Users\proyecto-test> git push |
git pull, git merge origin/main |
Sincronizar la rama con el remoto | |
Pull Request |
Solicitar una Revisión de Cambios | En la plataforma de Github, una vez que se ha hecho el push, se puede solicitar una revisión de estos cambios antes de unirlo al repositorio principal, para esto GitHUb tiene una opción que se llama "pull request " ó PR, (solicitud de revisión), accedes a esta opción y solicitas un pull request hacia la rama que quieres enviar el cambio, digamos que quiero mandar el cambio a la rama "qa", ejecutas esta acción y el dueño del Repo o la persona que creó el Repo como el TL, por ejemplo acepta el cambio para mergearlo con la rama "main", o sea sincroniza la rama con los cambios que creaste, o te puede mandar una notificación comentando sobre algún problema o un desacuerdo. Hacer el PR y establecerlo como parte del flujo para el SCV es una buena prática, pero no significa que sea obligatorio, puedes enviar los cambios directamente y listo. Esto sería determinado en el flujo de CI/CD que se aborda en el siguiente tema. |
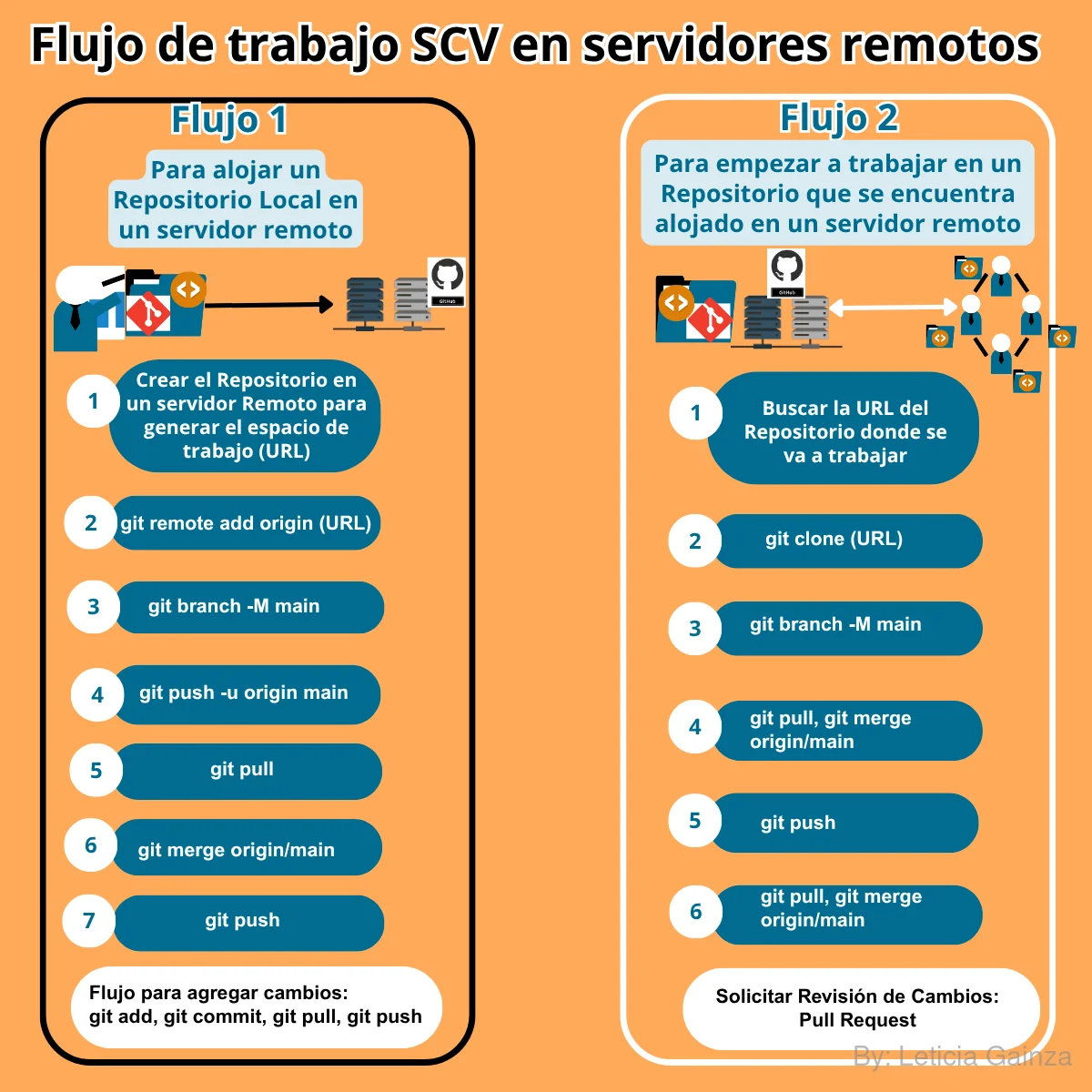
Flujo de trabajo con Ramas en SDLC
El SDLC usando un SCV se basa en el flujo de trabajo donde se crean ramas para desarrollar las funcionalidades del proyecto, testearlas, integrarlas y enviarlas a producción. Este flujo se organiza según las necesidades de cada proyecto, las herramientas que se utilizan para los repositorios remotos y la cultura de cada organización en las prácticas de las diferentes etapas del SDLC.
En este tema voy a explicar una de las herramientas que ofrece Github, que permiten organizar el flujo de trabajo en el SCV y las ramas dentro del proyecto: Gitflow
Este es un modelo de desarrollo de software basado en ramas, que además es una de las funcionalidades que ofrece Github. Es una herramienta que propicia una estructa de flujos diseñada para trabajar con ramas, con comandos para crear una estructura de ramas desde CLI usando Git.
Gitflow se trata de un sistema que recomendado para organizar el flujo de trabajo en el SCV y las ramas dentro del proyecto, permitiendo crear las ramas y eliminarlas, esto va a contribuir luego a la organización de los flujos para automatizar CI/CD.
En la web de Github se muestra toda la documentación para entender esto, el flujo más básico sería el siguiente:
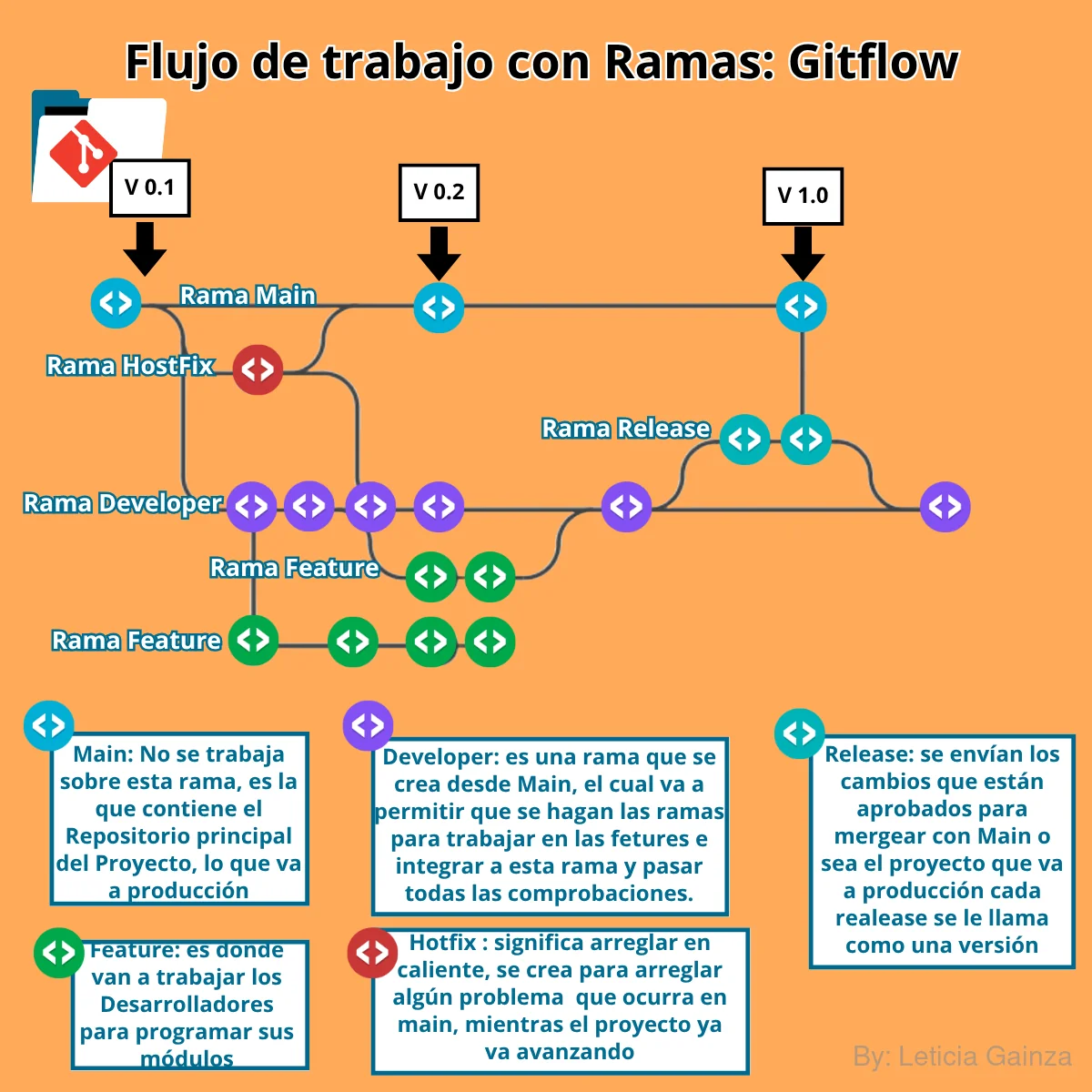
Otra buena práctica es eliminar una rama de trabajo temporal una vez que se haya cerrado un ciclo de trabajo, supongamos que se había creado en el repo una rama para una funcionalidad y de esta se crearon otras para cada feature, a medida se van desarrollando y aprobando los cambios deberían eliminarse del Repo, esto lo haría la persona con esos permisos.
Trabajo colaborativo sin Autorización para cambios
Github también permite acceder a Proyectos que son de acceso libre, en algunos casos para colaborar, ahí puedes clonar, enviar cambios y solicitar un pull request.
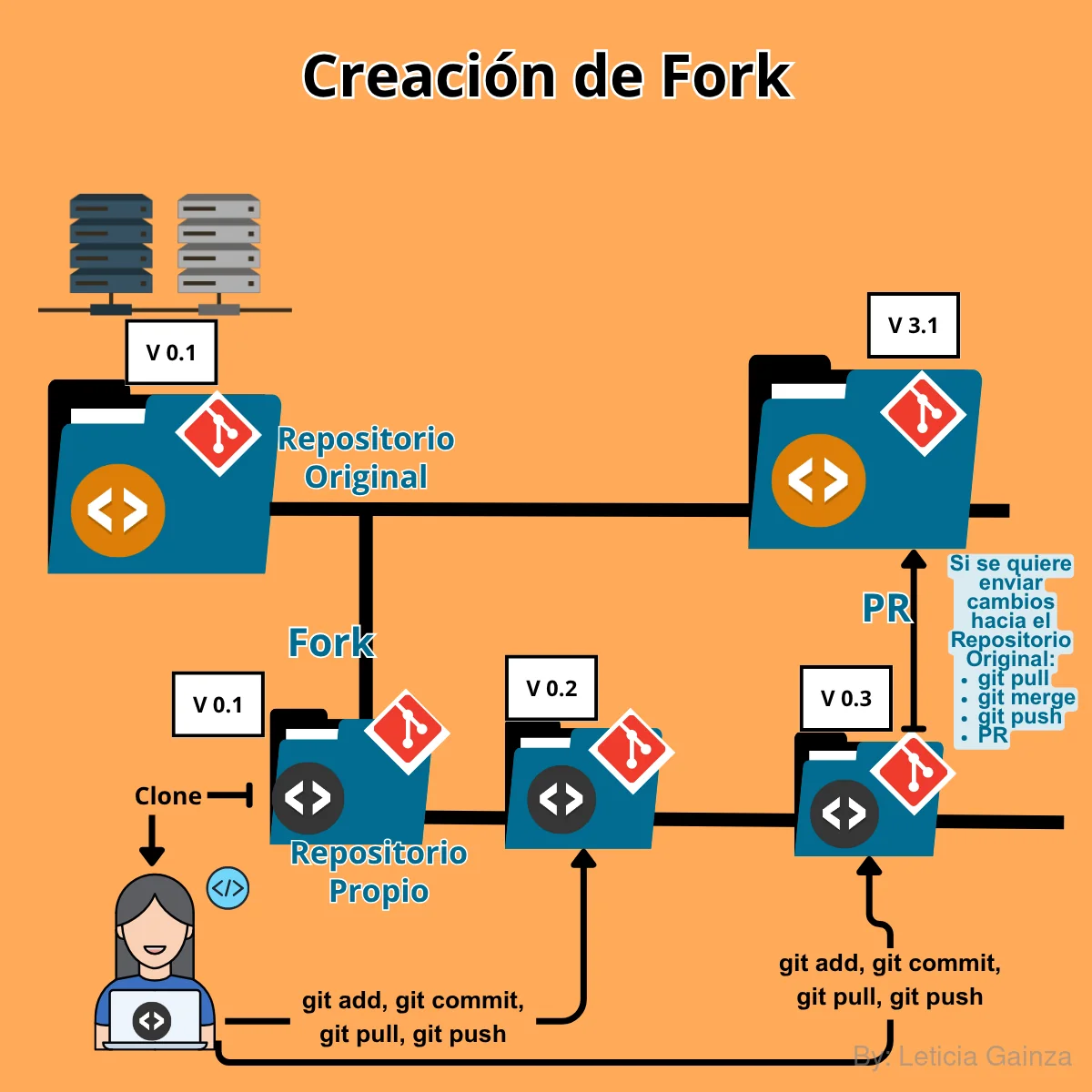
Pero si quisieras trabajar en un proyecto con acceso libre, hacer cambios sin pedir autorización, lo recomendable es crear una copia individual de el repositorio, esto es posible desde tu perfil de Github haciendo un Fork . Se accede al Repositorio de tu interés, y en la interfaz en el menú superior a la derecha, aparece la opcion "Fork", haciendo click en esta puedes usar una funcionalidad que permite hacer una bifurcación o sea separar una copia idéntica para trabajar sin tener permisos para hacer cambios en el repo original, esta copia va a aparecer en tu perfil, como un proyecto propio pero, que fue un fork hecho de otro proyecto.
Al hacer el fork, puedes continuar con el flujo de trabajo habitual de tu proyecto y si quieres hacer cambios, tienes la opción para clonar el Repositorio y descargarlo en el equipo local.
Cada vez que hagas un commit y realizas un push, hacia este Repositorio remoto, no se va a necesitar hacer un PR. Además, Github ofrece, la opción de sincronizar el repo bifurcado con el original, por si le han hecho cambios, esa es otra de las funcionalidades que propicia la plataforma, así te puedes traer las últimas actualizaciones. En caso de que sí quieras sincronizar y enviar los cambios hechos en tu fork hacia el Repositorio original, si necesitarías solicitar un PR hacia este.